ArgoCD de A à Y

Le GitOps
Qu’est-ce que le GitOps?
Le GitOps est une méthodologie où Git va être au centre des processus d’automatisation de livraison. Celui-ci fait office de “source de vérité” et va être couplé à des programmes pour continuellement comparer l’infrastructure actuelle avec celle décrite dans le dépôt Git.
Il ne faut pas le confondre avec le CI-CD qui consiste à tester le code applicatif et à le livrer. En effet, le GitOps reprend ce même procédé mais en embarquant d’autres aspects de l’architecture applicative :
- Infrastructure as code.
- Policy as code.
- Configuration as code.
- Et bien d’autres éléments X-as-Code.
Gestion d’une infrastructure
Exemple :
Je souhaite faciliter l’administration de mon infrastructure AWS. Il m’est possible de configurer des comptes pour que les dix membres de mon équipe puissent modifier et créer des instances EC2 et les security-groups.
Ce fonctionnement est une méthodologie simple et facile d’usage mais reste quelques zones d’ombres :
- Comment savoir qui a modifié cette instance EC2 et pourquoi ?
- Comment reproduire exactement la même infrastructure pour créer des environnements de dev / staging ?
- Comment être sûr que la configuration de l’infrastructure est bien la dernière à jour ?
- À des fins de tests ou de débogage, comment revenir à une version antérieure de la configuration ?
Pour répondre à ces problématiques, il est courant d’utiliser des logiciels de gestion d’infrastructure et/ou gestion de configuration comme Ansible ou Terraform et de limiter les modifications manuelles.
Mais ces logiciels ne font pas tout. Une fois la configuration écrite, il faut quelqu’un pour l’appliquer à chaque fois que celle-ci est mise à jour. Apparaissent alors de nouvelles questions :
- Qui doit lancer les scripts ? Quand ? Comment ?
- Comment garder une trace des déploiements ?
- Comment être sûr que la configuration lancée est bien la dernière ?
- Comment tester cette configuration avant de la déployer ?
La majorité des questions trouve réponse assez facilement en couplant ces logiciels avec des outils de CI-CD (Jenkins, Gitlab CI, Github Actions etc.). On se retrouve alors à coupler le monde du développement avec celui de l’administration du SI.
Et c’est justement ça le GitOps : une méthodologie qui va permettre d’utiliser Git pour gérer l’infrastructure en utilisant des outils de développement pour l’administrer.
Pull vs Push
Dans l’univers du GitOps, il existe deux modes de fonctionnement distincts : le Push et le Pull. Ces modes désignent l’acteur qui va s’occuper de synchroniser l’infrastructure avec le code ( ce qu’on appelera la boucle de réconciliation).
Par exemple, en mode Push : Jenkins peut déployer l’infrastructure en appelant Terraform comme l’aurait fait un administrateur système.
En mode Pull : c’est l’infrastructure qui va elle-même chercher sa configuration sur le dépôt Git. Un exemple un peu bateau serait un conteneur qui va lui-même télécharger sa configuration sur un dépôt Git (oui, c’est pas courant et peu efficace, mais cela correspond bien à notre définition).
Ces deux modes possèdent des avantages et des inconvénients que nous allons détailler ci-après.
Mode Push
Le mode Push est le plus simple à mettre en place et s’interface souvent avec des outils déjà présents dans la stack technique (Terraform, Puppet, Saltstack, Ansible etc.).
En revanche, il demande à ce que les identifiants/secrets nécessaires pour administrer notre environnement technique soient utilisables par le runner CI-CD ou quelque part dans le pipeline de déploiement (qui peut être un point de vulnérabilité).
Ainsi, l’acteur lançant le programme de déploiement devient sensible et il convient de sécuriser au maximum la supply-chain pour ne pas que cette machine dévoile les accès.
Mode Pull
En mode Pull, l’acteur déployant l’infrastructure est lui-même présent à l’intérieur de celle-ci. Compte tenu de sa nature, il possède déjà les accès pour réaliser son devoir : comparer le Git avec l’environnement technique et s’assurer que les deux soient en accord.
L’avantage est que le Git est donc totalement propre de toute donnée sensible. Le principal défaut dans ce système est qu’il peut être complexe à mettre en place et que tout environnement n’est pas forcément compatible.
La boucle de réconciliation
Une notion importante dans le GitOps est la boucle de réconciliation. C’est le processus qui va permettre de comparer l’état actuel de l’infrastructure avec celui décrit dans le dépôt Git.
Celle-ci est composée de trois étapes :

- Observe :
- Récupérer le contenu du dépôt Git.
- Récupérer l’état de infrastructure.
- Diff :
- Comparer le dépôt avec l’infrastructure.
- Act :
- Réconcilier l’architecture avec le contenu du Git.
Git dans “GitOps”
Avec cette méthodologie, on peut toujours profiter de Git pour l’utiliser comme il a été pensé : un outil collaboratif. L’usage des Merge-Request est un réel atout pour permettre à des acteurs de proposer des modifications dans la branche principale (celle synchronisée avec l’infra) en permettant aux “sachants” d’approuver ou refuser ces modifications.
En traitant la configuration ou l’architecture comme du code, on gagne en fiabilité et on bénéficie des mêmes avantages que les développeurs : historisation, organisation, collaboration.
Le GitOps dans Kubernetes
Kubernetes est un bel exemple de ce qu’on peut faire avec le GitOps dès son usage le plus basique : la création et le déploiement de manifests YAML/JSON contenant les instructions que Kubernetes doit appliquer pour la création d’une application.
Il est ainsi possible d’appliquer les deux modes de fonctionnement du GitOps :
- Push - Faire un
kubectl applydirectement dans un Pipeline Gitlab. - Pull - Un pod récupérant régulièrement (via un
git pull) le contenu d’un dépôt et disposant des permissions suffisantes pour appliquer les manifests si un commit les mets à jour.
Aujourd’hui, nous allons justement tester un des deux grands outils permettant de faire du GitOps : ArgoCD
Quand réconcilier l’infrastructure ?
Cette problématique est la même que lors de la partie “déploiement” du CI-CD. Quand devons-nous réconcilier notre dépôt Git avec nos machines ?
Comme tout bon SRE, je vais vous répondre “ça dépend”.
En fonction de ce que coûte un déploiement, il peut convenir de limiter les interactions pour ne déployer que de gros changements (voire une succession de modifications mineures).
Remarque
Par “coût”, je parle bien évidemment d’argent, mais aussi de potentiels “downtime” causés par la boucle de réconciliation.
Un déploiement à chaque commit peut être intéressant mais très couteux tandis qu’un déploiement chaque nuit (où peu d’utilisateurs sont présents) peut demander de l’organisation pour tester le déploiement.
Les trois façons de faire sont donc :
- Réconcilier à chaque modification dans la branche principale.
- Réconcilier chaque X temps.
- Réconcilier manuellement.
Astuce
Il convient de faire ses commits dans une branche annexe avant de la merge dans la branche principale pour lancer le déploiement. Ainsi, un commit peut contenir de nombreuses modifications.
ArgoCD
Fonctionnement de ArgoCD
ArgoCD est l’un des programmes permettant de comparer le contenu d’un cluster avec celui d’un dépôt Git. Il a l’avantage d’être simple à utiliser et extrêmement flexible pour les équipes.
Qu’est-ce qu’ArgoCD ?
ArgoCD est un programme permettant de comparer une source de vérité sur Git avec un cluster Kubernetes. Il dispose de nombreuses fonctionnalitées comme :
- La détection automatique de Drift (si un utilisateur a manuellement modifié le code directement sur le cluster).
- Une interface WebUI pour l’administration du cluster.
- La possibilité de gérer plusieurs clusters.
- Une CLI pour administrer l’ArgoCD.
- Contient un exporteur Prometheus natif.
- Permet de faire des actions antes/post réconciliation.
Installation
ArgoCD est un programme qui s’installe sur un cluster Kubernetes, et ce de plusieurs manières :
- Un bundle complet avec WebUI et CLI,
- Un bundle minimal avec seulement les CRDs.
Dans cet article, je vais installer un ArgoCD complet (avec WebUI et CLI) sur un cluster Kubernetes.
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
Pour accéder à notre ArgoCD fraîchement installé (que ce soit par WebUI ou CLI), il nous faut un mot de passe. Celui-ci est généré automatiquement et stocké dans un secret Kubernetes.
Obtenir le mot de passe par défaut :
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -d
Vous pouvez maintenant créer un proxy pour accéder à la Webui (ou utiliser un service LoadBalancer / Ingress).
Information
Si vous souhaitez exposer le service d’ArgoCD dans un Ingress/HTTPRoute, vous devrez certainement désactiver le TLS :
kubectl patch configmap argocd-cmd-params-cm -n argocd --type merge --patch '{"data": {"server.insecure": "true"}}'
Administrer ArgoCD en CLI
Installer la CLI
En dehors de Pacman, l’utilitaire en ligne de commande n’est pas disponible dans les dépôts de la majorité des distributions. Il est donc nécessaire de le télécharger manuellement.
curl -sSL -o argocd-linux-amd64 https://github.com/argoproj/argo-cd/releases/latest/download/argocd-linux-amd64
sudo install -m 555 argocd-linux-amd64 /usr/local/bin/argocd
rm argocd-linux-amd64
D’autres méthodes d’installation sont disponibles sur la documentation officielle
Se connecter à ArgoCD
Il est possible de se connecter de plusieurs manières à ArgoCD, la plus simple étant de se connecter avec des identifiants :
- Utiliser un mot de passe :
argocd login argocd.une-pause-cafe.fr
- Utiliser le kubeconfig :
argocd login --core
- Utiliser un token :
argocd login argocd.une-pause-cafe.fr --sso
Déployer sa première application avec ArgoCD
On ne va pas aller trop vite en besogne, alors commençons par ce que ArgoCD sait faire de mieux : déployer une application, ni plus ni moins.
Pour cela, plusieurs manières sont possibles :
- Utiliser la WebUI
- Utiliser la CLI ArgoCD
- Utiliser le CRD
Application
Dans cet article, je vais fortement privilégier l’utilisation des CRDs pour déployer des applications (voire même des projets) car c’est le seul composant qui sera toujours présent avec ArgoCD. La CLI et la WebUI sont optionnelles et peuvent être désactivées mais pas les CRDs.
Si vous ne savez pas quoi déployer, je vous propose plusieurs applications de test sur mon dépôt Git : Kubernetes Coffee Image
Ce dépôt contient plusieurs applications déployables de nombreuses manières : Helm, Kustomize, ou même des manifests bruts.
Créons alors notre première application avec l’image la plus simple : time-coffee qui affiche simplement une image de café ainsi que l’hostname du pod.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: simple-app
namespace: argocd
spec:
destination:
namespace: simple-app
server: https://kubernetes.default.svc
project: default
source:
path: simple/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
Que fait ce manifest ? Il déploie une application nommée simple-app à partir des fichiers disponibles sur le dépôt Git au chemin simple/chart.
ArgoCD n’a pas besoin qu’on lui indique les fichiers à sélectionner (le dossier suffit) ou même le format de ceux-ci (kustomize, helm etc.). Il va automatiquement détecter la nature de ces fichiers et appliquer les modifications en conséquence.
En retournant sur l’interface web d’ArgoCD (ou en utilisant la CLI), vous devriez voir votre application au statut OutOfSync. Cela signifie que l’application n’est pas encore déployée sur le cluster.
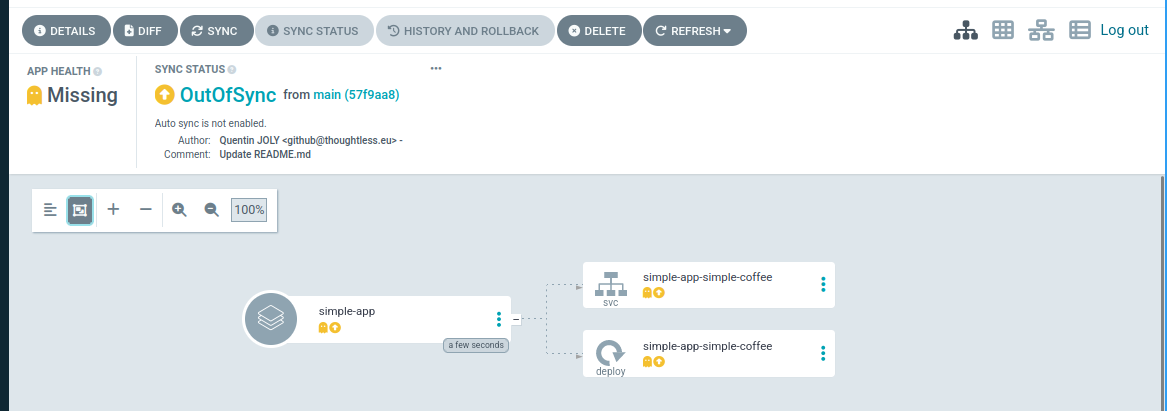
$ argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/simple-app https://kubernetes.default.svc simple-app default OutOfSync Missing <none> <none> https://github.com/QJoly/kubernetes-coffee-image simple/chart main
Pour forcer la réconciliation (et donc le déploiement de l’application), il suffit de cliquer sur le bouton “Sync” dans l’interface WebUI ou de lancer la commande argocd app sync simple-app.
Après quelques secondes (le temps que Kubernetes applique les modifications), l’application devrait être déployée et son statut devrait être Synced.
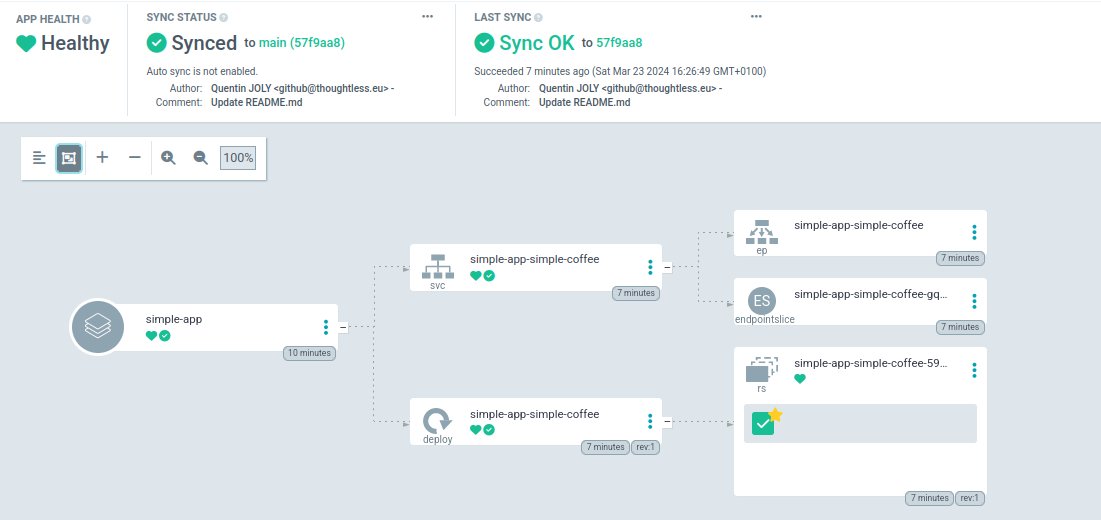
Vous avez maintenant la base pour déployer une application avec ArgoCD.
Rafraichir le dépôt chaque X temps
Par défaut, ArgoCD va rafraichir le contenu du dépôt toutes les 3 minutes. Il est possible de changer ce comportement pour réduire la charge sur le cluster si ArgoCD est utilisé pour de nombreux projets (ou si le cluster est très sollicité).
Information
À savoir que le rafraichissement du dépôt n’implique pas la réconciliation de l’application. Il faudra activer l’option auto-sync pour cela.
Pour ce faire, il faut valoriser la variable d’environnement ARGOCD_RECOCILIATION_TIMEOUT dans le pod argocd-repo-server (qui utilise lui-même la variable timeout.reconciliation dans la configmap argocd-cm).
$ kubectl -n argocd describe pods argocd-repo-server-58c78bd74f-jt28g | grep "RECONCILIATION"
ARGOCD_RECONCILIATION_TIMEOUT: <set to the key 'timeout.reconciliation' of config map 'argocd-cm'> Optional: true
Mettre à jour la configmap argocd-cm pour changer la valeur de timeout.reconciliation :
kubectl -n argocd patch configmap argocd-cm -p '{"data": {"timeout.reconciliation": "3h"}}'
kubectl -n argocd rollout restart deployment argocd-repo-server
Ainsi, le rafraichissement du Git sera fait toutes les 3 heures. Si la reconciliation automatique est activée et qu’il n’y a pas de fenêtre de synchronisation, le cluster sera réconcilié toutes les 3 heures.
Rafraîchir le dépôt à chaque commit
À l’inverse de la réconciliation régulière, il est possible de rafraîchir le Git automatiquement à chaque modification du code. Pour cela, on utilise un webhook que l’on va paramétrer sur Github / Gitlab / Bitbucket / Gitea etc.
Une étape optionnelle (mais que je trouve indispensable) est de créer un secret pour qu’ArgoCD n’accepte les webhooks que lorsqu’ils possèdent ce secret.
Information
Ne pas mettre en place ce secret revient à laisser n’importe qui déclencher une réconciliation sur le cluster et donc DoS le pod ArgoCD.
Je choisi la valeur monPetitSecret que je vais convertir en Base64 (obligatoire pour les secrets Kubernetes) :
$ echo -n "monPetitSecret123" | base64
bW9uUGV0aXRTZWNyZXQ=
En fonction du serveur Git utilisé la clé utilisée par ArgoCD va être différente :
- Github :
webhook.github.secret - Gitlab :
webhook.gitlab.secret - Gog/Gitea :
webhook.gog.secret
J’utilise Github (donc la clé webhook.github.secret) :
kubectl -n argocd patch cm argocd-cm -p '{"data": {"webhook.github.secret": "bW9uUGV0aXRTZWNyZXQ="}}'
kubectl rollout -n argocd restart deployment argocd-server
Ensuite, je vais sur mon dépôt Github, dans Settings > Webhooks et je crée un nouveau webhook. Je choisi le type application/json et mets l’URL de mon cluster Kubernetes (ou le service LoadBalancer / Ingress) suivi de /api/webhook (par exemple https://argocd.moncluster.com/api/webhook).
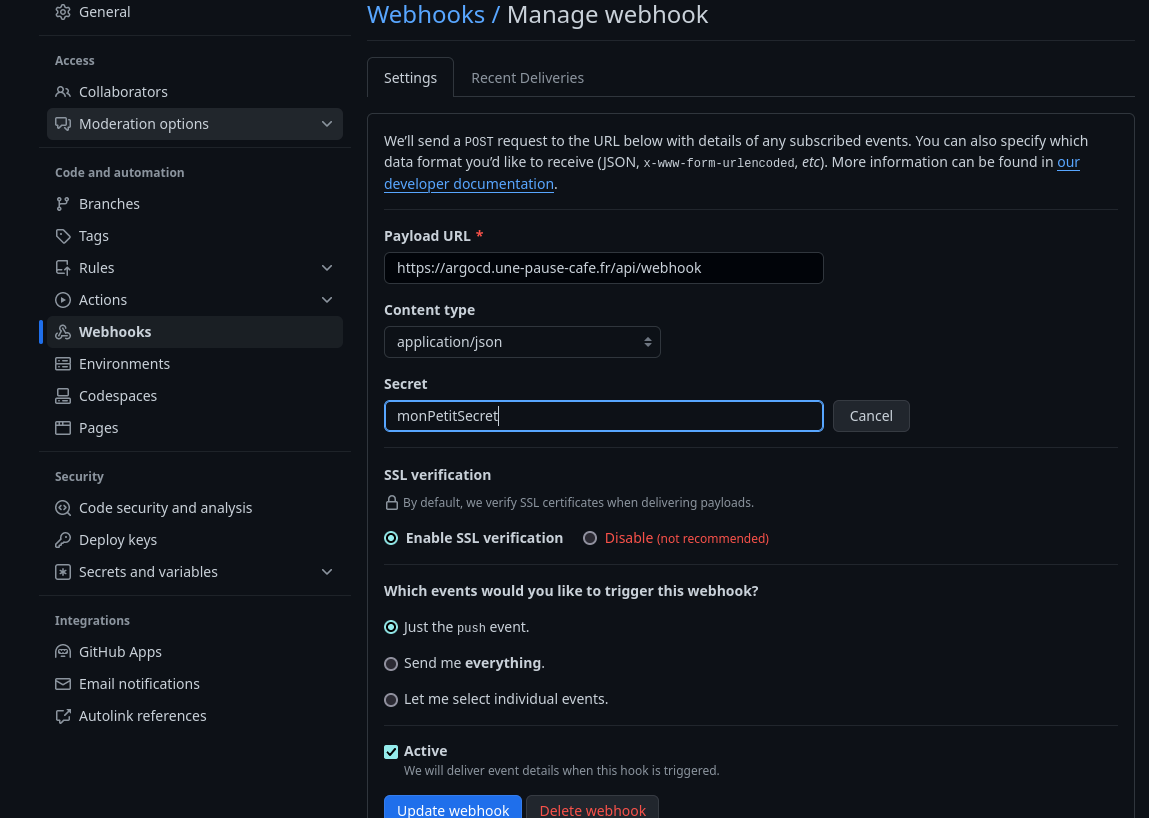
Avertissement
Si la console ArgoCD affiche l’erreur Webhook processing failed: HMAC verification failed à la reception d’un webhook, les raisons peuvent être multiples :
- Le secret n’est pas le bon.
- Le secret contient des caractères spéciaux qui ne sont pas bien interprétés.
- La requête n’est pas en Json.
Après avoir utilisé un secret aléatoire, j’ai dû le changer pour un secret plus simple ne comportant que des caractères simples : a-zA-Z0-9.
Stratégie de synchronisation
Il est possible de définir de nombreux paramètres pour la synchronisation des applications.
Auto-Pruning
Cette fonctionnalité est très intéressante pour éviter de garder des ressources inutiles dans le cluster. Lors d’une réconciliation, ArgoCD va supprimer les ressources qui ne sont plus présentes dans le dépôt Git.
Pour l’activer depuis la ligne de commande :
argocd app set argocd/simple-app --auto-prune
Ou depuis le manifest de l’application (à mettre dans le spec de l’application) :
syncPolicy:
automated:
prune: true
Self-Heal
Le self-heal est une fonctionnalité qui permet de réconcilier automatiquement le cluster si une ressource est modifiée manuellement. Par exemple, si un utilisateur modifie un secret, ArgoCD va remarquer cette différence entre le cluster et la source de vérité avant de supprimer ce delta.
Pour l’activer depuis la ligne de commande :
argocd app set argocd/simple-app --self-heal
Ou depuis le manifest de l’application (à mettre dans le spec de l’application) :
syncPolicy:
automated:
selfHeal: true
Les Health Checks
Lorsqu’ArgoCD réconcilie le cluster avec le dépôt Git, il va afficher un statut de santé pour chaque application (Healthy, Progressing, Degraded, Missing). Au début je ne m’en suis pas trop préoccupé mais il peut être intéressant de comprendre ce que ces statuts signifient et comment ArgoCD les détermine.
Pour les objets comme les secrets ou les configmaps, la présence de l’objet dans le cluster est suffisante pour que l’entité soit Healthy. Pour un service de type LoadBalancer, ArgoCD va vérifier que le service est bien exposé sur l’IP attendue en vérifiant sur la valeur status.loadBalancer.ingress n’est pas vide.
Il est possible de créer ses propres Healthchecks pour des objets non présents dans la liste des objets supportés par ArgoCD en créant un petit code en Lua dans la configmap argocd-cm :
Un exemple (disponible dans la documentation de ArgoCD) pour les certificats gérés par cert-manager :
resource.customizations: |
cert-manager.io/Certificate:
health.lua: |
hs = {}
if obj.status ~= nil then
if obj.status.conditions ~= nil then
for i, condition in ipairs(obj.status.conditions) do
if condition.type == "Ready" and condition.status == "False" then
hs.status = "Degraded"
hs.message = condition.message
return hs
end
if condition.type == "Ready" and condition.status == "True" then
hs.status = "Healthy"
hs.message = condition.message
return hs
end
end
end
end
hs.status = "Progressing"
hs.message = "Waiting for certificate"
return hs
Ignorer les ressources crées automatiquement
Dès que je déploie un Chart Helm, Cilium va automatiquement me créer un objet CiliumIdentity dans le cluster (utilisé pour créer des règles de pare-feu directement avec le nom du chart). Cette ressource n’est pas présente dans mon dépôt Git et ArgoCD n’apprécie pas trop cette différence.
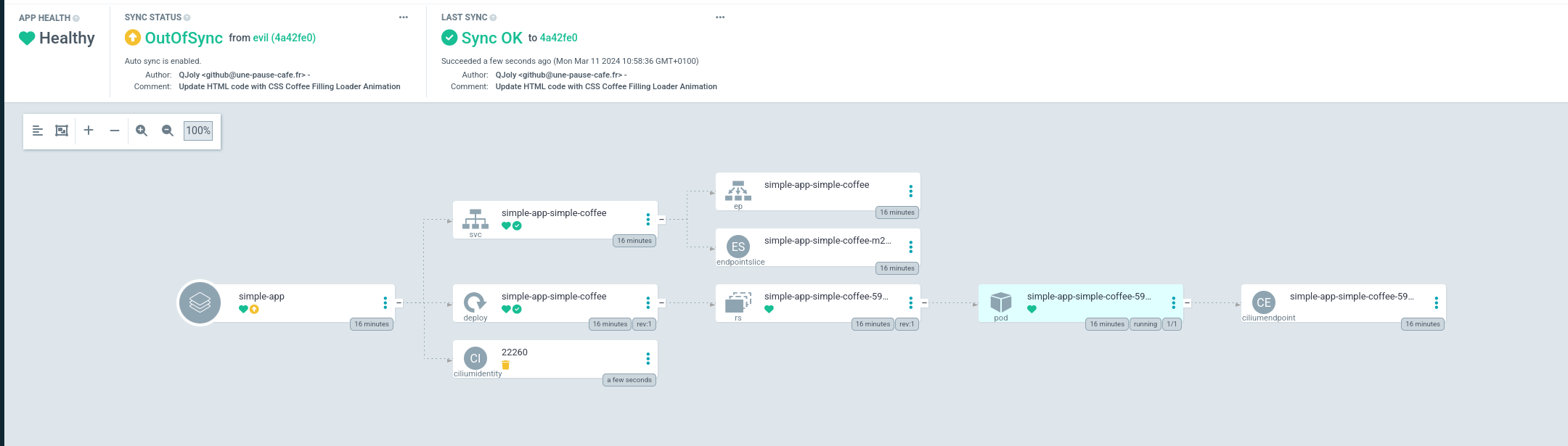
C’est pourquoi il m’est possible de lui demander de systématiquement ignorer les ressources d’un certain type. Pour cela, je vais modifier la configmap argocd-cm pour ajouter une exclusion.
resource.exclusions: |
- apiGroups:
- cilium.io
kinds:
- CiliumIdentity
clusters:
- "*"
Après un redémarrage d’ArgoCD (kubectl -n argocd rollout restart deployment argocd-repo-server), il ne devrait plus afficher cette différence.
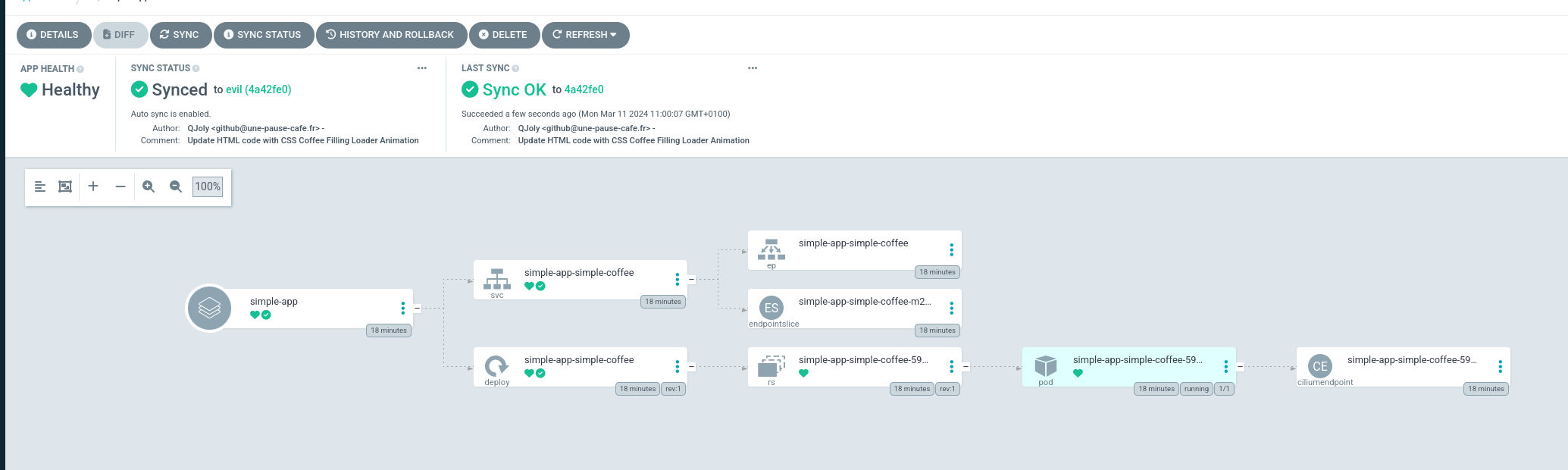
J’aurais voulu que cette option soit paramétrable par application, mais il n’est pas possible de le faire actuellement.
Surcharger les variables
Une fonctionnalité obligatoire pour la majorité des applications est la surcharge des variables directement depuis ArgoCD. Cela permet de ne pas avoir à modifier le dépôt Git pour changer une valeur et ne pas s’imposer les contraintes de la configuration par défaut.
Il existe de nombreuses manières de surcharger les variables dans ArgoCD. Voici un exemple pour Kustomize :
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
project: default
source:
repoURL: 'https://github.com/QJoly/kubernetes-coffee-image'
path: evil-tea/kustomize
targetRevision: evil
kustomize:
patches:
- patch: |-
- op: replace
path: /metadata/name
value: mon-mechant-deploy
target:
kind: Deployment
name: evil-tea-deployment
destination:
server: 'https://kubernetes.default.svc'
namespace: evil-ns
Et sur Helm :
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
destination:
namespace: versioned-coffee
server: https://kubernetes.default.svc
project: default
source:
helm:
parameters:
- name: service.type
value: NodePort
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
Déployer une application sur plusieurs clusters
Pour le moment, nous n’utilisons qu’un seul et unique cluster : celui sur lequel ArgoCD est installé. Mais il est possible de déployer une application sur plusieurs clusters sans avoir à installer un second ArgoCD.
Pour cela, il est possible de le configurer facilement avec l’utilitaire en ligne de commande (une seconde manière est de générer plusieurs secrets formant l’équivalent d’un kubeconfig).
Je vais créer un second cluster et le configurer dans mon fichier local ~/.kube/config :
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* admin@homelab-talos-dev homelab-talos-dev admin@homelab-talos-dev argocd
admin@temporary-cluster temporary-cluster admin@temporary-cluster default
Mon cluster sera donc temporary-cluster et je vais le configurer dans ArgoCD à partir de la commande argocd cluster add [nom du context]. Celui-ci va se charger de créer un service account sur le cluster pour qu’il puisse le gérer à distance.
$ argocd cluster add admin@temporary-cluster
WARNING: This will create a service account `argocd-manager` on the cluster referenced by context `admin@temporary-cluster` with full cluster level privileges. Do you want to continue [y/N]? y
INFO[0017] ServiceAccount "argocd-manager" created in namespace "kube-system"
INFO[0017] ClusterRole "argocd-manager-role" created
INFO[0017] ClusterRoleBinding "argocd-manager-role-binding" created
INFO[0022] Created bearer token secret for ServiceAccount "argocd-manager"
Cluster 'https://192.168.1.97:6443' added
En retournant sur l’interface WebUI, je peux voir que mon second cluster est bien présent.
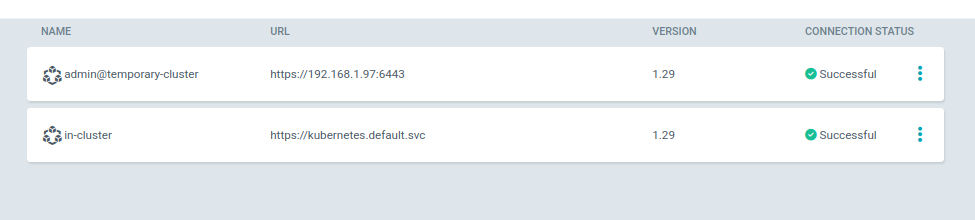
$ argocd cluster list
SERVER NAME VERSION STATUS MESSAGE PROJECT
https://192.168.1.97:6443 admin@temporary-cluster 1.29 Successful
https://kubernetes.default.svc in-cluster
Lorsque j’ajoute une application dans ArgoCD, je peux maintenant sélectionner le cluster sur lequel je veux la déployer.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
destination:
namespace: versioned-coffee
server: https://192.168.1.97:6443
project: default
source:
helm:
parameters:
- name: service.type
value: NodePort
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
Les Applications Set
Les Applications Set sont une fonctionnalité d’ArgoCD permettant de créer des templates d’applications. L’idée est d’avoir un template d’application qui va être dupliqué pour chaque élément d’une liste.
Voici quelques exemples d’utilisation :
- Déployer la même application dans plusieurs namespaces.
- Déployer la même application sur plusieurs clusters.
- Déployer la même application avec des valeurs différentes.
- Déployer plusieurs versions d’une application.
Pour créer un Application Set, il suffit de créer un fichier YAML contenant la liste des applications à déployer.
Par exemple, si je souhaite déployer toutes les versions de mon application versioned-coffee dans 3 namespaces différents :
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: versioned-coffee
namespace: argocd
spec:
generators:
- list:
elements:
- namespace: alpha
tag: v1.1
- namespace: dev
tag: v1.2
- namespace: staging
tag: v1.3
- namespace: prod
tag: v1.4
template:
metadata:
name: versioned-coffee-{{namespace}}
spec:
project: default
source:
helm:
parameters:
- name: image.tag
value: {{tag}}
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
destination:
namespace: {{namespace}}
server: 'https://kubernetes.default.svc'
syncPolicy:
automated:
selfHeal: true
syncOptions:
- CreateNamespace=true
Après quelques secondes : je dispose bien de 4 applications versioned-coffee déployées dans 4 namespaces différents.
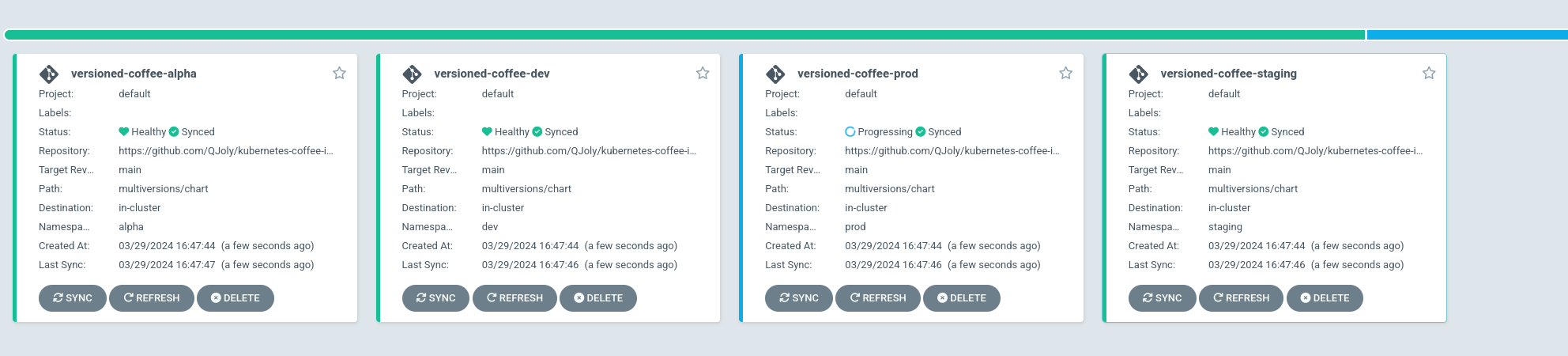
Mais l’usage d’une liste statique n’est pas la seule manière de créer un ApplicationSet. Il est possible d’utiliser des sources externes comme ‘Générateurs’ pour créer des applications dynamiques :
- La liste des clusters Kubernetes connectés à ArgoCD.
- Un dossier dans un dépôt Git (
./apps/charts/*). - L’intégralité des dépôts Git d’un utilisateur / organisation.
- Déployer les pull-requests sur un dépôt Git.
- Une API externe (par exemple, un service de ticketing).
Il est aussi possible de coupler les générateurs ensembles pour créer des applications plus complexes.
Pour déployer une application sur plusieurs clusters, je peux utiliser le générateur cluster. Je peux alors déployer une application sur tous les clusters, ou seulement sur ceux que je souhaite cibler.
Pour choisir l’intégralité des clusters, il suffit de mettre une liste vide :
generators:
- clusters: {}
Je peux également sélectionner les clusters en fonction du nom :
generators:
- clusters:
names:
- admin@temporary-cluster
Ou un label sur le secret (secret créé par argocd cluster add) :
# Avec un match sur le label staging
generators:
- clusters:
selector:
matchLabels:
staging: true
# Ou avec les matchExpressions
generators:
- clusters:
matchExpressions:
- key: environment
operator: In
values:
- staging
- dev
Durant cette démonstratino, je dispose de deux clusters dans ArgoCD : production-cluster-v1 et staging-cluster-v1.
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* admin@core-cluster core-cluster admin@core-cluster argocd
admin@production-cluster-v1 production-cluster-v1 admin@production-cluster-v1 default
admin@staging-cluster-v1 staging-cluster-v1 admin@staging-cluster-v1 default
$ argocd cluster list
SERVER NAME VERSION STATUS MESSAGE PROJECT
https://192.168.1.98:6443 staging-cluster-v1 1.29 Successful
https://192.168.1.97:6443 production-cluster-v1 1.29 Successful
https://kubernetes.default.svc in-cluster
Je vais créer l’applicationSet qui va déployer l’application simple-coffee sur les clusters dont le secret contient le label app: coffee.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: simple-coffee
namespace: argocd
spec:
generators:
- clusters:
selector:
matchLabels:
app: coffee
template:
metadata:
name: 'simple-coffee-{{name}}'
spec:
project: default
source:
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
destination:
namespace: simple-coffee
server: '{{server}}'
syncPolicy:
automated:
selfHeal: true
syncOptions:
- CreateNamespace=true
Si on regarde les applications déployées, on constate que l’application n’est déployée sur aucun cluster (car aucun ne possède le label app: coffee).
argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
On va ajouter ce label au secret du cluster staging-cluster-v1.
kubectl label -n argocd secrets cluster-staging-v1 "app=coffee"
Instantanément, l’application simple-coffee-staging-cluster-v1 est ajoutée à ArgoCD et déployée sur le cluster staging-cluster-v1 (et uniquement sur celui-ci).
staging-cluster-v1
$ argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/simple-coffee-staging-cluster-v1 https://192.168.1.98:6443 simple-coffee default Synced Healthy Auto <none> https://github.com/QJoly/kubernetes-coffee-image multiversions/chart main
Avertissement
Dans le manifest ci-dessus, j’ai utilisé la variable {{name}} pour récupérer le nom du cluster. Mais si celui-ci contient des caractères spéciaux, il faudra mettre à jour ce nom pour qu’il respecte la RFC 1123.
Par défaut, lorsqu’on ajoute un cluster à ArgoCD via la commande argocd cluster add, le nom du cluster est le nom du contexte.
Par exemple, si le nom de mon cluster est admin@production-cluster-v1, je peux le renommer avec le traitement suivant :
secretName="cluster-production-v1-sc" # Nom du secret utilisé par ArgoCD pour stocker les informations du cluster
clusterName=$(kubectl get secret ${secretName} -n argocd -o jsonpath="{.data.name}" | base64 -d) # admin@production-cluster-v1
clusterName=$(echo ${clusterName} | sed 's/[^a-zA-Z0-9-]/-/g') # admin-production-cluster-v1
kubectl patch -n argocd secret ${secretName} -p '{"data":{"name": "'$(echo -n ${clusterName} | base64)'"}}'
Le nouveau nom du cluster sera alors admin-production-cluster-v1.
Si jamais je veux déployer l’application sur le cluster de production, il me suffit de lui ajouter le label app: coffee :
kubectl label -n argocd secrets cluster-production-v1 "app=coffee"
$ argocd app list
NAME CLUSTER NAMESPACE PROJECT STATUS HEALTH SYNCPOLICY CONDITIONS REPO PATH TARGET
argocd/simple-coffee-admin-production-cluster-v1 https://192.168.1.97:6443 simple-coffee default Synced Healthy Auto <none> https://github.com/QJoly/kubernetes-coffee-image multiversions/chart main
argocd/simple-coffee-staging-cluster-v1 https://192.168.1.98:6443 simple-coffee default Synced Healthy Auto <none> https://github.com/QJoly/kubernetes-coffee-image multiversions/chart main
Et si je veux retirer l’application du cluster de staging, je retire le label :
kubectl label -n argocd secrets cluster-staging-v1-sc app-
ArgoCD Image Updater
ArgoCD Image Updater est un outil permettant de mettre à jour automatiquement les images des applications déployées par ArgoCD.
Pourquoi ? Parce qu’à chaque fois qu’une nouvelle image est disponible, il faudrait modifier le manifest pour la mettre à jour. C’est une tâche fastidieuse et qui peut être automatisée par du CI-CD ou par ArgoCD Image Updater.
L’objectif est donc de déléguer cette tâche à ArgoCD qui va régulièrement vérifier si une nouvelle image est disponible et la mettre à jour si c’est le cas.
Cette mise à jour, il peut la faire de plusieurs manières :
- En surchargeant les variables du manifest (Helm, Kustomize) dans l’application ArgoCD.
- En créant un commit sur le dépôt Git pour que ArgoCD le prenne en compte (ce qui nécessite d’avoir un accès en écriture sur le dépôt Git).
Il convient également de se pencher sur les questions suivantes: “Quelle image va-t’on utiliser ?” et “Comment savoir si une nouvelle image est disponible ?”.
ArgoCD Image Updater peut être configuré de quatre façon différentes :
semver: Pour les images utilisant le format de versionnement sémantique (1.2.3) dans le tag.latest: Toujours utiliser la dernière image créée (peu importe son tag).digest: Mettre à jour le digest de l’image (en conservant le même tag).name: Mettre à jour le tag de l’image en utilisant le dernier tag dans l’ordre alphabétique (peut également se coupler avec une regex pour ne pas prendre en compte certains tags).
Installation
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj-labs/argocd-image-updater/stable/manifests/install.yaml
Configuration
Pour cette démonstration, je vais me baser sur la méthode semver.
Mon dépôt comporte plusieurs images avec des tags de versionnement sémantique : v1, v2, v3 et v4. Ce ne sont que des applications PHP afficheant un café pour l’image v1, deux pour l’image v2, trois pour v3 etc.
Créons donc une application ArgoCD utilisant l’image v1 (utilisée par défaut dans le chart).
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: versioned-coffee
namespace: argocd
spec:
destination:
namespace: versioned-coffee
server: https://kubernetes.default.svc
project: default
source:
helm:
parameters:
- name: service.type
value: NodePort
path: multiversions/chart
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: main
syncPolicy:
syncOptions:
- CreateNamespace=true
Par défaut, mon fichier values.yaml utilise l’image qjoly/kubernetes-coffee-image:v1.
En ouvrant le NodePort de notre application, on peut voir que l’image v1 est bien déployée (il y a bien un seul café).
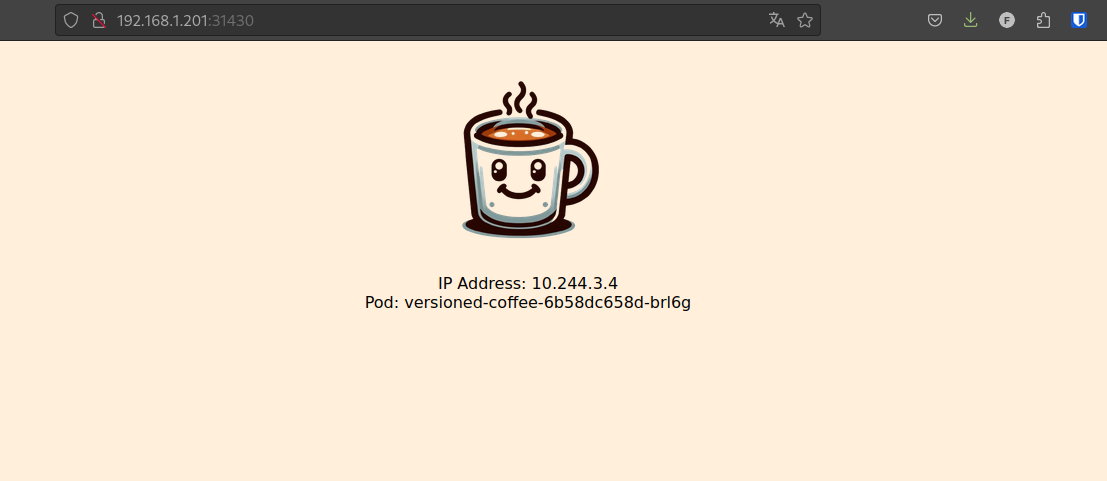
En tant qu’administrateur du cluster, si j’apprends qu’une nouvelle image est disponible, je peux aller mettre à jour mon application ArgoCD pour qu’elle utilise un nouveau tag correspondant à la nouvelle image.
argocd app set versioned-coffee --parameter image.tag=v2
Cela va avoir pour effet de surcharger la variable image.tag dans le fichier values.yaml de mon application Helm.
project: default
source:
repoURL: 'https://github.com/QJoly/kubernetes-coffee-image'
path: multiversions/chart
targetRevision: main
helm:
parameters:
- name: service.type
value: NodePort
- name: image.tag
value: v2
destination:
server: 'https://kubernetes.default.svc'
namespace: versioned-coffee
syncPolicy:
syncOptions:
- CreateNamespace=true
Admettons que nous soyons sur une plateforme de développement ayant besoin d’être à jour, cela devient vite fastidieux de mettre à jour manuellement le tag à chaque fois qu’une nouvelle version est disponible.
C’est là qu’intervient ArgoCD Image Updater. Celui-ci peut automatiser le fait de mettre à jour les tags des images en fonction de la méthode choisie.
On ajoute une annotation à notre application ArgoCD pour lui indiquer qu’il doit surveiller les images de notre dépôt.
kubectl -n argocd patch application versioned-coffee --type merge --patch '{"metadata":{"annotations":{"argocd-image-updater.argoproj.io/image-list":"qjoly/kubernetes-coffee-image:vx"}}}'
En ajoutant l’annotation argocd-image-updater.argoproj.io/image-list avec la valeur qjoly/kubernetes-coffee-image:vx, je demande à ArgoCD Image Updater de surveiller les images de mon dépôt.
Par défaut, celui-ci va automatiquement mettre à jour la clé image.tag et image.name dans le fichier values.yaml de mon application Helm.
Information
Si votre values.yaml possède une syntaxe différente (par exemple, le tag est à la clé app1.image.tag, il est quand même possible de mettre à jour cette clé).
argocd-image-updater.argoproj.io/image-list: coffee-image=qjoly/kubernetes-coffee-image:vx
argocd-image-updater.argoproj.io/coffee-image.helm.image-name: app1.image.name
argocd-image-updater.argoproj.io/coffee-image.helm.image-tag: app1.image.tag
Sur l’interface web, ArgoCD m’indique que le dépôt est Out of sync. Un clic sur le bouton Sync permet de mettre à jour le tag de l’application :

Vous pouvez coupler ça à une synchronisation automatique si nécessaire.
Application d’applications
ArgoCD permet de déployer des applications qui vont en déployer d’autres. C’est un peu le principe de la “composition” en programmation.
Pourquoi faire ça ? Pour déployer des applications qui ont des dépendances entre elles. Par exemple, si je veux déployer une application qui a besoin d’une base de données, je peux déployer la base de données avec ArgoCD et ensuite déployer l’application.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: applications
namespace: argocd
spec:
destination:
server: https://kubernetes.default.svc
project: default
source:
path: argocd-applications
repoURL: https://github.com/QJoly/kubernetes-coffee-image
targetRevision: HEAD
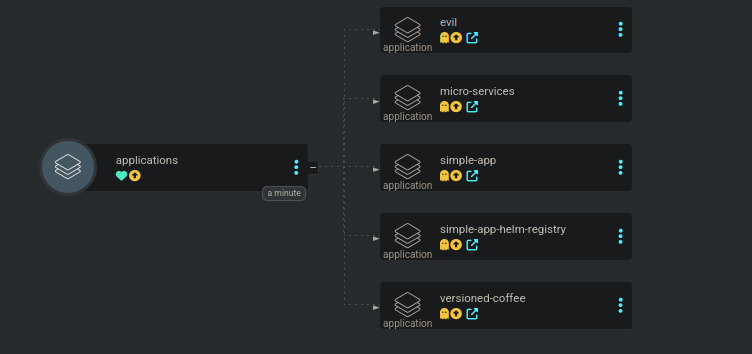
Créer des utilisateurs
ArgoCD permet de créer des utilisateurs pour se connecter à l’interface web. Il est possible de se connecter avec des identifiants, avec un token ou avec un SSO.
Pour créer un utilisateur, je dois l’ajouter directement dans la configmap argocd-cm :
kubectl -n argocd patch configmap argocd-cm --patch='{"data":{"accounts.michele": "apiKey,login"}}'
Cette commande permet de créer un utilisateur michele pouvant générer des tokens d’API en son nom et se connecter avec un mot de passe à l’interface web de ArgoCD.
Pour assigner un mot de passe à cet utilisateur, je dois utiliser la commande argocd account update-password --account michele.
Maintenant, Michèle ne peut rien faire sur mon ArgoCD, elle ne peut ni créer, ni consulter les applications, corrigeons cela.
Le système RBAC d’ArgoCD fonctionne avec un principe de policies que je vais assigner à un utilisateur ou un rôle.
Une policy peut autoriser une action à un utilisateur ou à un groupe. Ces actions peuvent se décomposer de plusieurs façon :
- Droits sur une ‘application’ précise (
projet/application). - Droits sur une ‘action’ précise ( ex:
p, role:org-admin, logs, get, *, allow(récupérer les logs de toutes les applications)).
Je vais créer un rôle guest qui sera limité à la lecture seule sur toutes les applications du projet default.
policy.csv: |
p, role:guest, applications, get, default/*, allow
g, michele, role:guest
Maintenant, je souhaite qu’elle puisse synchroniser l’application simple-app dans le projet default:
policy.csv: |
p, role:guest, applications, get, default/*, allow
p, michele, applications, sync, default/simple-app, allow
g, michele, role:guest
Créer un projet et gérer les droits
Un projet est un groupement d’applications auquel nous pouvons assigner des rôles et des utilisateurs. Cela permet de gérer les droits de manière plus fine et de limiter les accès à certaines applications.
Michèle travaille dans le projet Time-Coffee et a besoin de droits pour créer et administrer des applications dans ce projet.
Ces applications seront limitées au namespace time-coffee du cluster sur lequel argocd est installé et elle ne pourra pas voir les applications des autres projets.
En tant qu’administrateur, je vais également limiter les dépôts Git utilisables sur ce projet.
Créons d’abord le projet Time-Coffee :
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: time-coffee
namespace: argocd
spec:
clusterResourceWhitelist:
- group: '*'
kind: '*'
destinations:
- name: in-cluster
namespace: '*'
server: https://kubernetes.default.svc
sourceNamespaces:
- time-coffee
sourceRepos:
- https://github.com/QJoly/kubernetes-coffee-image
- https://git.internal.coffee/app/time-coffee
- https://git.internal.coffee/leonardo/projects/time-coffee
Je peux maintenant créer un rôle time-coffee-admin pour Michèle et time-coffee-developper (uniquement dans le projet time-coffee).
p, role:time-coffee-admin, *, *, time-coffee/*, allow
g, michele, role:time-coffee-admin
p, role:time-coffee-developper, applications, sync, time-coffee/*, allow
p, role:time-coffee-developper, applications, get, time-coffee/*, allow
Je vais ajouter le développeur “Leonardo” qui travaille également sur le projet Time-Coffee. Il n’a besoin que de synchroniser les applications après avoir push sur le dépôt Git.
g, leonardo, role:time-coffee-developper
Le projet Time-Coffee est maintenant prêt à être utilisé par Michèle et Leonardo sans qu’ils puissent accéder aux ressources des autres namespaces.
… Ou peut-être que non ?
Le mot de passe de Leonardo se fait compromettre et un vilain pirate arrive à se connecter à ArgoCD avec ses identifiants. Par chance, le pirate ne peut que lancer une synchronisation sur les applications du projet Time-Coffee. Mais il arrive à se connecter au compte Github de Leonardo et souhaite pirater le cluster complet pour y miner des cryptomonnaies.
Comme j’ai autorisé tout les types de ressources : le pirate peut modifier les fichiers présents sur le dépôt Git pour créer un ClusterRole avec des droits d’administration sur le cluster suivi d’un pod déployant son malware.
Dans cet exemple, l’application ‘pirate’ ne fait qu’afficher les pods des autres namespaces. Mais il aurait pu faire bien pire.
L’erreur se trouve dans le fait que j’ai autorisé tous les types de ressources pour le projet Time-Coffee. Par défaut, ArgoCD va volontairement bloquer les objets ClusterRole et ClusterRoleBinding pour garantir l’isolation des projets.
Je supprime alors la whitelist pour les ressources cluster :
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: time-coffee
namespace: argocd
spec:
destinations:
- name: in-cluster
namespace: '*'
server: https://kubernetes.default.svc
sourceNamespaces:
- time-coffee
sourceRepos:
- https://github.com/QJoly/kubernetes-coffee-image
- https://git.internal.coffee/app/time-coffee
- https://git.internal.coffee/leonardo/projects/time-coffee
Réconcilier les applications à une heure précise
En fonction du temps de travail de vos équipes, il peut être intéressant de réconcilier les applications à une heure précise. Par exemple, réconcilier les applications à minuit pour éviter de perturber les utilisateurs.
Pour cela, il est possible de créer une règle de réconciliation dans les projets ArgoCD.
Information
À noter que cette règle s’applique pour les réconciliations automatiques et manuelles.
Je peux ajouter le champ syncWindows dans le manifest de mon projet ArgoCD pour définir une fenêtre de réconciliation.
syncWindows:
- kind: allow # autoriser de 6h à 12h
schedule: '0 6 * * *'
duration: 6h
timeZone: 'Europe/Paris'
applications:
- 'time-coffee-*'
- kind: deny
schedule: '* * * * *'
timeZone: 'Europe/Paris'
applications:
- 'time-coffee-*'
À partir de 12h, le nouveau champ ‘Sync Windows’ montre qu’il n’est pas possible de réconcilier le cluster avec la source de vérité durant cette période.

Remarque
Il est possible d’autoriser les synchronisations manuelles dans les cas de force majeure.
Il faut normalement rajouter l’option manualSync: true dans la fenêtre où l’on souhaite l’autoriser. Mais je n’ai pas réussi dans mon cas (Bug ? Erreur de config ? ).
Les Hooks
Lorsqu’on donne des fichiers à déployer dans un cluster, ArgoCD va les déployer selon un ordre précis. Il commence par les namespaces, les ressources Kubernetes, et enfin les CustomResourceDefinitions (CRD).
L’ordre est défini directement en statique dans le code
Il est possible de modifier cet ordre en utilisant les Hooks qui se décomposent eux mêmes en Phases (PreSync, Sync, PostSync …) et en Sync Wave (qui permettent de définir l’ordre de déploiement des applications avec un nombre dans une même phase).
Les phases
Les phases sont les suivantes:
PreSync, avant la synchronisation (ex: Vérifier si les conditions sont réunies pour déployer).Sync, pendant la synchronisation, c’est la phase par défaut lorsqu’aucune phase n’est précisée.PostSync, après la synchronisation (ex: Vérifier que le déploiement s’est bien passé).SyncFail, à la suite d’une erreur de synchronisation (ex: Faire un rollback du schéma de la base de données).PostDelete, après la suppression de l’application ArgoCD (ex: Nettoyer des ressources externes à l’application).
Ces phases sont configurées directement dans les fichiers Yaml via des annotations argocd.argoproj.io/hook.
apiVersion: v1
kind: Pod
metadata:
name: backup-db-to-s3
annotations:
argocd.argoproj.io/hook: PreSync
argocd.argoproj.io/hook-delete-policy: HookSucceeded
spec:
containers:
- name: backup-container
image: amazon/aws-cli
command: ["/bin/sh"]
args: ["-c", "aws s3 cp /data/latest.sql s3://psql-dump-coffee/backup-db.sql"]
volumeMounts:
- name: db-volume
mountPath: /data
volumes:
- name: db-volume
persistentVolumeClaim:
claimName: db-psql-dump
Habituellement, les hooks sont utilisés pour lancer des tâches destinées à être supprimées une fois que leur travail est terminé. Pour les supprimer automatiquement une fois qu’ils ont terminés, il est possible d’utiliser l’annotation argocd.argoproj.io/hook-delete-policy: HookSucceeded.
Afin de laisser le temps aux ressources d’une phase d’être prêtes avant de passer à la phase suivante, ArgoCD laisse un temps d’attente de 2 secondes entre chaque phase.
Astuce
Pour configurer ce temps, il est possible de modifier la variable d’environnement ARGOCD_SYNC_WAVE_DELAY dans le pod ArgoCD.
Les Sync Waves
Durant une même phase, il est possible de définir un ordre de déploiement des applications avec un nombre dans une même phase avec l’annotation argocd.argoproj.io/sync-wave. Par défaut, toutes les ressources ont un sync-wave à 0 et ArgoCD commencera par les ressources avec le sync-wave le plus faible.
Pour déployer une application avant une autre, il suffit donc de mettre un sync-wave plus faible (ex: -1).
Chiffrer ses manifests
En écrivant cet article, je souhaitais cibler l’absence de chiffrement des fichiers yaml comme le ferait le combo kustomize+sops avec FluxCD. Mais durant un live sur CuistOps, Rémi m’a orienté vers KSOPS, un plugin kustomize qui permet de chiffrer les fichiers yaml à la volée (durant un kustomize build).
Bien sûr, des solutions comme SealedSecrets ou Vault sont préférables. Mon besoin est de pouvoir utiliser des charts Helm n’acceptant pas d’utiliser des ConfigMaps / Secrets externes aux charts.
Contrairement à d’autres alternatives, KSOPS ne nécessite pas d’utiliser une image modifiée d’ArgoCD pour fonctionner. Il est sous la forme d’un patch à appliquer sur le déploiement de l’application ArgoCD pour modifier les binaires du conteneur argocd-repo-server.
Installation de KSOPS
La première chose à faire est d’activer les plugins alpha dans kustomize et autoriser l’exécution de commandes dans les fichiers kustomization.yaml.
Pour ce faire, il faut patcher la configmap de l’application ArgoCD pour ajouter les arguments --enable-alpha-plugins et --enable-exec. ArgoCD récupère ces arguments dans la ConfigMap argocd-cm.
kubectl patch configmap argocd-cm -n argocd --type merge --patch '{"data": {"kustomize.buildOptions": "--enable-alpha-plugins --enable-exec"}}'
Ensuite on peut modifier le Deployment de l’application ArgoCD pour ajouter KSOPS et un kustomize modifié (contenant le plugin kustomize viaduct.ai/v1 ) via les initContainers.
Créons le fichier patch-argocd-repo-server.yaml :
# patch-argocd-repo-server.yaml
kind: Deployment
metadata:
name: argocd-repo-server
namespace: argocd
spec:
template:
spec:
initContainers:
- name: install-ksops
image: viaductoss/ksops:v4.3.1
securityContext.runAsNonRoot: true
command: ["/bin/sh", "-c"]
args:
- echo "Installing KSOPS and Kustomize...";
mv ksops /custom-tools/;
mv kustomize /custom-tools/kustomize ;
echo "Done.";
volumeMounts:
- mountPath: /custom-tools
name: custom-tools
- name: import-gpg-key
image: quay.io/argoproj/argocd:v2.10.4
command: ["gpg", "--import","/sops-gpg/sops.asc"]
env:
- name: GNUPGHOME
value: /gnupg-home/.gnupg
volumeMounts:
- mountPath: /sops-gpg
name: sops-gpg
- mountPath: /gnupg-home
name: gnupg-home
containers:
- name: argocd-repo-server
env:
- name: XDG_CONFIG_HOME
value: /.config
- name: GNUPGHOME
value: /home/argocd/.gnupg
volumeMounts:
- mountPath: /home/argocd/.gnupg
name: gnupg-home
subPath: .gnupg
- mountPath: /usr/local/bin/ksops
name: custom-tools
subPath: ksops
- mountPath: /usr/local/bin/kustomize
name: custom-tools
subPath: kustomize
volumes:
- name: custom-tools
emptyDir: {}
- name: gnupg-home
emptyDir: {}
- name: sops-gpg
secret:
secretName: sops-gpg
Puis appliquons le patch directement sur le déploiement argocd-repo-server :
kubectl patch deployment -n argocd argocd-repo-server --patch "$(cat patch-argocd-repo-server.yaml)
La nouvelle version du pod argocd-repo-server devrait être bloqué en attente de la clé GPG.
$ kubectl describe -n argocd --selector "app.kubernetes.io/name=argocd-repo-server" pods
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned argocd/argocd-repo-server-586779485d-kw2j6 to rpi4-02
Warning FailedMount 108s (x12 over 10m) kubelet MountVolume.SetUp failed for volume "sops-gpg" : secret "sops-gpg" not found
Créer une clé GPG pour KSOPS
Il est possible d’utiliser une clé GPG ou Age pour chiffrer nos fichiers avec SOPS (la documentation de KSOPS propose les deux cas).
Pour ce tutoriel, je vais utiliser une clé GPG. Je vous invite à dédier une clé GPG à KSOPS/ArgoCD pour des raisons de sécurité.
Avertissement
Si vous avez déjà une clé mais qu’elle possède un mot de passe : il ne sera pas possible de l’utiliser avec KSOPS.
Je vais générer une clé GPG sans date d’expiration dans le but de la stocker dans un secret Kubernetes.
export GPG_NAME="argocd-key"
export GPG_COMMENT="decrypt yaml files with argocd"
gpg --batch --full-generate-key <<EOF
%no-protection
Key-Type: 1
Key-Length: 4096
Subkey-Type: 1
Subkey-Length: 4096
Expire-Date: 0
Name-Comment: ${GPG_COMMENT}
Name-Real: ${GPG_NAME}
EOF
Maintenant récupérons l’ID de la clé GPG. Si vous avez une seule paire de clés dans votre trousseau, vous pouvez la récupérer directement avec la commande suivante :
GPG_ID=$(gpg --list-secret-keys --keyid-format LONG | grep sec | awk '{print $2}' | cut -d'/' -f2) # Si vous n'avez qu'une seule paire dans le trousseau
… sinon lancez la commande gpg --list-secret-keys et récupérez la chaine de caractère à la valeur “sec” (ex: GPG_ID=F21681FB17B40B7FFF573EF3F300795590071418).
En utilisant l’id de la clé que nous venons de générer, nous l’envoyons sur le cluster en tant que secret.
gpg --export-secret-keys --armor "${GPG_ID}" |
kubectl create secret generic sops-gpg \
--namespace=argocd \
--from-file=sops.asc=/dev/stdin
Chiffrer des fichiers
Je vais créer un simple fichier Deployment que je vais chiffrer avec KSOPS.
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple-coffee
labels:
app: simple-coffee
spec:
replicas: 1
selector:
matchLabels:
app: simple-coffee
template:
metadata:
labels:
app: simple-coffee
spec:
containers:
- name: nginx
image: qjoly/kubernetes-coffee-image:simple
ports:
- containerPort: 80
env:
- name: MACHINE_COFFEE
value: "Krups à grain"
Je souhaite chiffrer la partie “containers”, je vais créer le fichier .sops.yaml pour définir les champs à chiffrer et la clé à utiliser.
creation_rules:
- path_regex: sealed.yaml$
encrypted_regex: "^(containers)$"
pgp: >-
F21681FB17B40B7FFF573EF3F300795590071478
Ensuite, je vais demander à sops de chiffrer le fichier deployment.yaml avec la commande suivante : sops -i -e deployment.yaml.
Dans l’état actuel, notre fichier est bien chiffré mais est inutilisable par ArgoCD qui ne sait pas le déchiffrer (ni quels fichiers sont à déchiffrables).
Pour cela, je vais créer un fichier Kustomize qui va exécuter ksops sur deployment.yaml. C’est une syntaxe qu’ArgoCD pourra comprendre (il utilisera le binaire ksops ajouté par notre patch).
# secret-generator.yaml
apiVersion: viaduct.ai/v1
kind: ksops
metadata:
name: secret-generator
annotations:
config.kubernetes.io/function: |
exec:
path: ksops
files:
- ./deployment.yaml
L’api viaduct.ai/v1 est le plugin Kustomize (déjà présent dans le binaire kustomize que nous récupérons sur l’image contenant KSOPS).
J’ajoute ensuite le fichier kustomization.yaml qui indique la nature du fichier secret-generator.yaml comme étant un “générateur de manifest”.
# kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
generators:
- ./secret-generator.yaml
En mettant ça dans un dépôt Git, et en le donnant à ArgoCD, celui-ci va automagiquement déchiffrer le fichier sans nécessiter la moindre action manuelle.
J’ai publié mon dépôt de test sur GitHub si vous souhaitez tester par vous même (il vous faudra modifier les fichiers .sops.yaml et deployment.yaml pour qu’ils correspondent à votre clé GPG).
Cette méthode est un peu plus complexe que FluxCD(+sops), mais le besoin final est satisfait. Je note quand même qu’il faut maintenir le patch pour utiliser des images récentes d’ArgoCD (init-pod import-gpg-key et install-ksops).
Conclusion
Je suis très satisfait d’ArgoCD et de ses fonctionnalités. Il est très simple à installer et à configurer sans pour autant négliger les besoins des utilisateurs avancés.
Il reste néanmoins beaucoup à découvrir autour d’ArgoCD (Matrix generator, Dynamic Cluster Distribution, Gestion des utilisateurs via SSO …).
Durant mon premier brouillon de cet article, je ciblais le manque de chiffrement des fichiers YAML (là où FluxCD le propose nativement). Mais grâce à KSOPS (Merci Rémi ❤️), il est possible de chiffrer les fichiers YAML directement dans ArgoCD de manière transparente.
Je n’ai aucune raison pour ne pas migrer sur ArgoCD pour mes projets personnels ! 😄
Merci d’avoir lu cet article, j’espère qu’il vous a plu et qu’il vous a été utile. N’hésitez pas à me contacter si vous avez des questions ou des remarques.