Au final… qu’est-ce qu’un conteneur ?

Dès lors qu’on prononce le terme “conteneur”, on nous répond toujours “Docker”, voire “Podman”. Certains aliens parlent de “containerd” mais c’est tout.
Pourtant, Docker n’est pas apparu comme ça par magie. Il est le fruit de plusieurs années de développement et de recherche dans le domaine de la conteneurisation.
Dans cet article, nous allons voir les bases de ce qu’est un conteneur ainsi qu’une petite démonstration de LXC.
Qu’est-ce qu’un conteneur ?
Un conteneur est un environnement isolé du système d’exploitation. Il peut être utilisé comme ‘prison’ pour une application afin de s’assurer qu’elle n’ait pas accès à des informations sur l’hôte.
à l’origine, la commande chroot était LA méthode pour isoler une application. Celle-ci permet de déplacer la racine de votre session dans un répertoire en rendant ainsi la réelle racine “impossible” d’accès.
Isoler l’aborescence
La création d’un chroot se résume principalement à créer une arborescence sur laquelle nous allons pouvoir lancer un shell.
Je vais créer mon chroot dans le répertoire /opt/jail01.
sudo mkdir -p /opt/jail01
sudo mkdir -p /opt/jail01/{lib,lib64,usr/bin}
sudo cp /usr/bin/{bash,touch,ls,cat,rm} /opt/jail01/usr/bin/
sudo ln -s /usr/bin /opt/jail01/bin
Je peux copier autant de binaires que je souhaite, mais dans ce court exemple, je vais m’arreter à la base de la base : bash, touch, ls, cat, rm.
Je peux maintenant lancer mon chroot via la commande sudo chroot /opt/jail01/bin /bin/bash
et …
sudo chroot /opt/jail01/ /bin/bash
chroot: failed to run command '/bin/bash': No such file or directory
Pourtant … mon binaire /opt/jail01/bin/bash est bien présent, et devrait bien se lancer !
La raison à ce refus: il me manque les dépendances situées dans les dossiers /lib et /lib64.
Les dépendances de mon binaire bash sont visibles via la commande ldd:
ldd /opt/jail01/usr/bin/bash | grep -o '/lib.* '
/lib/x86_64-linux-gnu/libtinfo.so.6
/lib/x86_64-linux-gnu/libdl.so.2
/lib/x86_64-linux-gnu/libc.so.6
/lib64/ld-linux-x86-64.so.2
On va lancer une boucle pour copier chaque fichier dans l’arborescence de notre chroot.
for i in $(ldd /opt/jail01/usr/bin/bash | grep -o '/lib.* '); do sudo cp --parents "$i" /opt/jail01/; done
Super, maintenant il nous reste quand même nos 4 autres binaires ! Vous comprenez maintenant pourquoi je me suis limité dans le nombre de commandes ajoutées.
Histoire de ne pas rendre le processus trop lourd, profitons du bash pour automatiser l’injection des librairies dans notre chroot.
for bin in $(ls /opt/jail01/usr/bin/); do
echo $bin
for lib in $(ldd /opt/jail01/usr/bin/$bin | grep -o '/lib.* '); do sudo cp -v --parents "$lib" /opt/jail01/; done
done
Voici le résultat attendu:
bash
'/lib/x86_64-linux-gnu/libtinfo.so.6' -> '/opt/jail01/lib/x86_64-linux-gnu/libtinfo.so.6'
'/lib/x86_64-linux-gnu/libdl.so.2' -> '/opt/jail01/lib/x86_64-linux-gnu/libdl.so.2'
'/lib/x86_64-linux-gnu/libc.so.6' -> '/opt/jail01/lib/x86_64-linux-gnu/libc.so.6'
'/lib64/ld-linux-x86-64.so.2' -> '/opt/jail01/lib64/ld-linux-x86-64.so.2'
cat
'/lib/x86_64-linux-gnu/libc.so.6' -> '/opt/jail01/lib/x86_64-linux-gnu/libc.so.6'
'/lib64/ld-linux-x86-64.so.2' -> '/opt/jail01/lib64/ld-linux-x86-64.so.2'
ls
'/lib/x86_64-linux-gnu/libselinux.so.1' -> '/opt/jail01/lib/x86_64-linux-gnu/libselinux.so.1'
'/lib/x86_64-linux-gnu/libc.so.6' -> '/opt/jail01/lib/x86_64-linux-gnu/libc.so.6'
'/lib/x86_64-linux-gnu/libpcre2-8.so.0' -> '/opt/jail01/lib/x86_64-linux-gnu/libpcre2-8.so.0'
'/lib/x86_64-linux-gnu/libdl.so.2' -> '/opt/jail01/lib/x86_64-linux-gnu/libdl.so.2'
'/lib64/ld-linux-x86-64.so.2' -> '/opt/jail01/lib64/ld-linux-x86-64.so.2'
'/lib/x86_64-linux-gnu/libpthread.so.0' -> '/opt/jail01/lib/x86_64-linux-gnu/libpthread.so.0'
rm
'/lib/x86_64-linux-gnu/libc.so.6' -> '/opt/jail01/lib/x86_64-linux-gnu/libc.so.6'
'/lib64/ld-linux-x86-64.so.2' -> '/opt/jail01/lib64/ld-linux-x86-64.so.2'
touch
'/lib/x86_64-linux-gnu/libc.so.6' -> '/opt/jail01/lib/x86_64-linux-gnu/libc.so.6'
'/lib64/ld-linux-x86-64.so.2' -> '/opt/jail01/lib64/ld-linux-x86-64.so.2'
On relance notre commande chroot :
sudo chroot /opt/jail01/
bash-5.0#
Yeah 😎 On a bien notre environnement isolé dans lequel nous ne pouvons pas accéder aux fichiers de notre hôte.
Mais sommes-nous vraiment dans un conteneur ?
Et bien … Non.
L’usage simple de chroot ne permet pas de créer un conteneur. Si j’enferme un programme dans un chroot, celui-ci aura toujours accès au maximum des ressources matérielles présentes sur ma machine.
Limiter l’usage des ressources
En 2006, Google développe les Cgroups, un des pilier de la conteneurisation actuelle. Celui-ci portait le nom initial conteneur de processus.
Cet utilitaire permet d’imposer des limites CPU/Mémoire à des processus et de prioriser certains processus.
Un usage simple est de limiter l’usage CPU sur un processus.
sudo apt install cgroup-tools
# Création des groupes fast et slow
sudo cgcreate -g cpu:/fast
sudo cgcreate -g cpu:/slow
# Appliquer la règle d'utiliser 25% du CPU sur slow, et 75% du CPU sur fast
sudo cgset -r cpu.shares=768 fast
sudo cgset -r cpu.shares=256 slow
Maintenant que nous avons nos groupes (et la règle limitant l’accès CPU), je peux lancer un programme gourmand comme stress en précisant le nombre de coeur de mon CPU (8 dans mon cas).
# dans un terminal 1
sudo cgexec -g cpu:fast stress --cpu 8
# dans un terminal 2
sudo cgexec -g cpu:slow stress --cpu 8
Résultat:
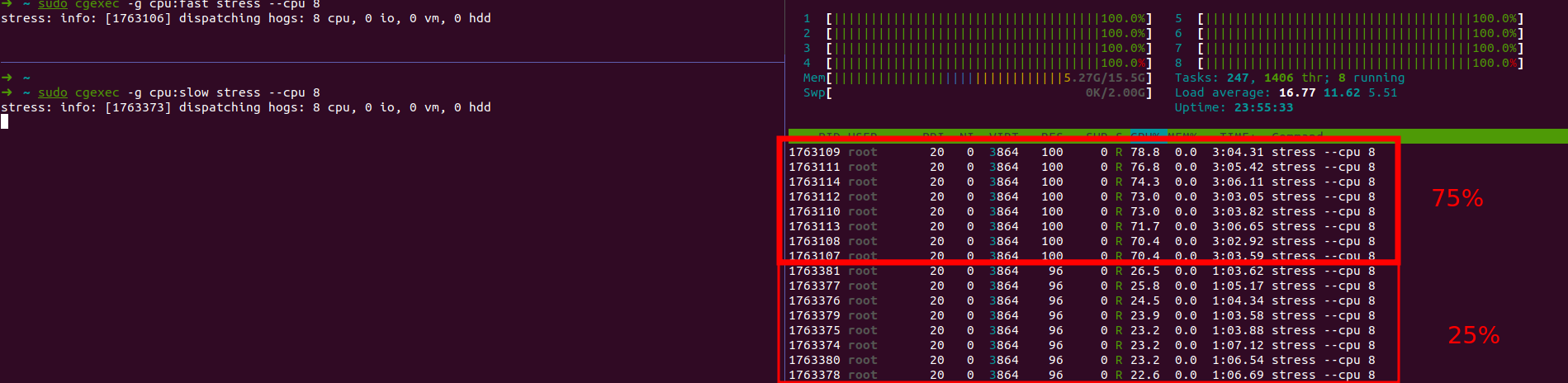
Lorsque je lance les processus stress on remarque bien deux groupes de processus : l’un ayant accès à 75% du CPU, l’autre à 25%.
Je peux aussi contrôler l’usage de la mémoire en créant un groupe limitant la RAM à 2G.
sudo cgcreate -g memory:limit
sudo cgset -r memory.limit_in_bytes=2g limit
Pour tester ça : je relance stress en créant 5 workers utilisant chacun 1G de mémoire (soit un total de 5Go).
sudo cgexec -g memory:limit stress -m 5 --vm-bytes 1G --vm-keep -t 30

Les processus se répartissent chacun ~500M pour un total de 2G, là où stress aurait dû utiliser 5Go sans la limitation.
Bien, nous arrivons à limiter les processus. Il m’est maintenant possible de limiter d’enfermer un programme dans un chroot tout en limitant l’accès aux ressources matérielles via la commande suivant:
sudo cgexec -g memory:limit -g cpu:/slow chroot /opt/jail01/
Notre prison est presque parfaite ! Qu’est-ce qu’il peut bien manquer ?
Isoler les processus
On a beau limiter les ressources ou changer la racine de l’arborescence, nos processus sont toujours libres.
Notre “prison” ne peut pas avoir son propre hostname et peut toujours utiliser notre adresse IP, il récupère ces informations de l’hôte.
bash-5.0# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp2s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether c8:d3:ff:a7:d9:b3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.1 scope global dynamic noprefixroute enp2s0
valid_lft 426129sec preferred_lft 426129sec
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:97:d5:5d:57 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker0
valid_lft forever preferred_lft forever
bash-5.0# hostname
MonHostname
Pour isoler notre environnement, il faut qu’on se repose sur les namespaces. Ce sont des filtres qui vont restreindre ce qu’un processus peut faire ou voir. Il en existe de nombreux types différents en fonction ce que l’on souhaite restreindre.
Voici certains namespaces couramment utilisés:
- Process Isolation (PID namespace). C’est une manière d’avoir plusieurs fois le même PID dans deux namespaces différents.
- Network (net namespace). Ce NS va autoriser un processus à avoir sa propre adresse IP.
- Unix Timesharing System (uts namespace). ⚠️ Son nom ne réprésente pas réellement son usage. Le UTS permet de contrôler les Network Information Service ou l’hostname.
- User Namespace. Permet à un processus de s’exécuter avec des privilèges limités à l’utilisateur.
- Montage (mnt namespace). Ajoute une couche d’isolation dans les points de montages en permettant aux utilisateurs d’avoir des montages invisibles pour les autres.
Pour revenir à notre problème d’Hostname et d’IP, nous avons 2 NS utilisables : l’uts et net.
Pour créer un NS où l’hostname sera différent que celui de la machine hôte, je peux utiliser la commande unshare (ne plus partager la ressource dans le sens littéral).
root@MonHostname:~# hostname
MonHostname
root@MonHostname:~# unshare --uts
root@MonHostname:~# hostname toto
root@MonHostname:~# hostname
toto
root@MonHostname:~# déconnexion
root@MonHostname:~# hostname
MonHostname
Note: le prompt ne change pas, mais l’hostname est bien différent.
Je peux aussi récupérer un faux PID 1 (normalement utilisé pour l’initialisation du système) via le PID NameSpace:
root@MonHostname:~# echo $$
554673
root@MonHostname:~# unshare --pid --fork --mount-proc
root@MonHostname:~# echo $$
1
Et laisser le conteneur avoir ses propres interfaces réseaux:
root@MonHostname:~# unshare --net
root@MonHostname:~# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Mais du coup, qu’est-ce qu’un conteneur ?
Un conteneur, c’est juste un regroupement des namespaces, des cgroups et du chroot. Une “boite” dans laquelle on peut mettre un processus et le limiter dans son usage.
Docker, Podman, LXC, Containerd, … sont tous des outils qui utilisent ces 3 éléments pour créer des conteneurs.
Utiliser LXC pour créer un conteneur
LXC est un outil de gestion de conteneur qui est apparu en 2008. LXC, contraction de l’anglais Linux Container, c’est un système de virtualisation, utilisant l’isolation comme méthode de cloisonnement au niveau du système d’exploitation. Il permet de créer des conteneurs légers, basés sur le noyau Linux.
Installation
LXC est disponible dans les dépôts officiels de Debian, Ubuntu et ArchLinux. Pour les autres distributions, il faudra se référer à la documentation officielle.
sudo apt-get install lxc
Activer RootLess
L’usage de LXC en rootless impose quand même certaines limitations. Les machines ne pourront pas intéragir avec des périphériques externes ou monter des partages distants en NFS.
Avant de commencer à aller dans le détail avec LXC, je souhaite pouvoir travailler en rootless (par sécurité). Durant l’installation, LXC va créer notre interface réseau lxcbr0 que nous devons modifier pour permettre à notre utilisateur d’ajouter d’autres interfaces sur ce bridge.
Nous allons déjà configurer notre interface lxcbr0, pour autoriser notre utilisateur à créer 10 sous-interfaces qui se lieront à notre principale:
echo "$(id -un) veth lxcbr0 10" | sudo tee -a /etc/lxc/lxc-usernet
à vous de personnaliser ce nombre pour créer +/- d’interfaces (en fonction de vos besoins).
La seconde étape à faire est de créer une plage d’UID/GID disponibles pour chaque utilisateur ayant besoin de créer des conteneurs. Un système Linux classique possède généralement une plage d’UID de 0 à 65535 (soit 65536 valeurs).
Sur Linux, il existe les fichiers /etc/subuid et /etc/subgid qui peuvent permettre à un utilisateur d’usurper une plage d’id et gid. Grâce à cette méthode, notre conteneur n’utiliseras pas la page 0 à 65536, mais 100000 à 165536.
Evidemment : cette différence d’id est invisible pour le conteneur. Celui-ci pensera bien utiliser une plage classique, mais il n’y a aucune chance qu’il ait un id commun avec un quelconque utilisateur de notre système hôte.
Vous devriez normalement déjà posséder une plage d’id à usurper. Sur mon Debian, voici le contenu de mes deux fichiers :
qjoly01:100000:65536
Pour garder cette même plage pour nos conteneurs, nous pouvons les injecter dans le fichier ~/.config/lxc/default.conf (que nous créons à partir du fichier /etc/lxc/default.conf) avec la syntaxe lxc.idmap = USER/GROUP 0 DEBUT_PLAGE TAILLE_PLAGE.
Pour faire ceci en batch, voici le script présent sur la documentation officielle de LinuxContainers.
mkdir -p ~/.config/lxc
cp /etc/lxc/default.conf ~/.config/lxc/default.conf
MS_UID="$(grep "$(id -un)" /etc/subuid | cut -d : -f 2)"
ME_UID="$(grep "$(id -un)" /etc/subuid | cut -d : -f 3)"
MS_GID="$(grep "$(id -un)" /etc/subgid | cut -d : -f 2)"
ME_GID="$(grep "$(id -un)" /etc/subgid | cut -d : -f 3)"
echo "lxc.idmap = u 0 $MS_UID $ME_UID" >> ~/.config/lxc/default.conf
echo "lxc.idmap = g 0 $MS_GID $ME_GID" >> ~/.config/lxc/default.conf
Voici le contenu complet de mon fichier de configuration:
lxc.net.0.type = veth
lxc.net.0.link = lxcbr0
lxc.net.0.flags = up
lxc.net.0.hwaddr = 00:16:3e:xx:xx:xx
lxc.idmap = u 0 100000 65536
lxc.idmap = g 0 100000 65536
Si votre FS supporte les ACLs (ext4, xfs, btrfs etc.), vous pouvez ajouter les permissions d’exécutions à l’id utilisé par LXC.
MS_UID="$(grep "$(id -un)" /etc/subuid | cut -d : -f 2)"
mkdir -p /home/$USER/.local/share/lxc
setfacl -m u:$MS_UID:x /home/$USER
setfacl -m u:$MS_UID:x /home/$USER/.local
setfacl -m u:$MS_UID:x /home/$USER/.local/share
setfacl -m u:$MS_UID:x /home/$USER/.local/share/lxc
Voir les images disponibles sur le registre publique images.linuxcontainers.org.
/usr/share/lxc/templates/lxc-download -l
Avertissement
J’ai eu certains problèmes en utilisant les images officielles Debian:
- La debian Trixie ne démarre pas.
- La debian Bookworm ne récupère pas d’IP via le DHCP en unprivilegied.
lxc-create -t download -n nom_conteneur -- -d debian -r trixie -a amd64
Par défaut, les conteneurs sont stockés à l’emplacement : /var/lib/lxc. En rootless (unprivilegied), ils se trouvent dans ~/.local/share/lxc.
Vous pouvez rentrer dans votre conteneur via la commande lxc-attach -n nom_conteneur.
root@bertha:~# lxc-attach nom_conteneur
root@nomconteneur:~# hostname
nomconteneur
root@nomconteneur:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
2: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 92:dc:ab:15:d6:86 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.16/24 metric 1024 brd 10.0.3.255 scope global dynamic eth0
valid_lft 3592sec preferred_lft 3592sec
inet6 fe80::90dc:abff:fe15:d686/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
Et après ?
Nous verrons dans un prochain article un usage plus poussé de LXC avec (par exemple) la création de notre propre image préconfigurée. Pour le moment : nous avons largement de quoi nous amuser avec ce que nous avons vu.
Pour un environnement de test, l’usage d’LXC direct est suffisant. Pour manager un parc de conteneurs, il est préférable d’utiliser un outil comme Incus.
Avertissement
Attention, le projet LXD n’appartient plus à Linux Containers depuis le 4 juillet 2023 et est maintenant géré par Canonical.
Conclusion
J’ai voulu faire cet article pour montrer que Docker n’est pas le seul outil de conteneurisation et qu’il n’y a pas de magie derrière. Les conteneurs sont utilisés depuis des années et sont devenus omniprésents dans notre quotidien mais ce n’est pas une raison pour oublier les fondations de notre stack technologique (c’était le pretexte pour que je creuse moi-même le sujet que je ne connaissais pas si bien que ça).
J’espère que cet article vous aura plu et que vous aurez appris des choses. N’hésitez pas à me faire un retour sur Twitter ou par mail si vous avez des questions ou des remarques.
Et pour ceux qui ne sont pas encore au courant, moi et le camarade Joël Séguillon avons créé une chaine Twitch dont le premier live aura lieu le 11 décembre à 21h. Nous parlerons de machines virtuelles dans Kubernetes et de comment les utiliser. N’hésitez pas à venir nous voir et à vous abonner à la chaine pour ne pas louper le live. Chaine Twitch Cuist’Ops
Le live est reporté à une date ultérieure. Je vous tiendrai au courant sur Twitter 😄