Présentation rapide de Docker-Swarm

Introduction
Le monde de la conteneurisation a apporté de nombreuses choses dans l’administration système, et a actualisé le concept de DevOps. Mais une des choses principales que nous apporte les conteneurs (et particulièrement Docker), c’est l’automatisation. Et bien que Docker soit déjà complet avec le déploiement de service, on peut aller un peu plus loin en automatisant la gestion des conteneurs ! Et pour répondre à ça : Docker Inc. propose un outil adapté pour l’orchestration automatique d’instance : Docker Swarm.
Qu’est ce que Docker Swarm ?
Comme dit précédemment : Docker Swarm est un outil d’orchestration. Avec cet outil, on peut gérer automatiquement nos conteneurs avec des règles favorisant la Haute-disponibilité, et l’évolutivité (Scalability) de vos services. On peut donc imaginer 2 scénarios qui sont entièrement compatibles :
- Votre site a un pic de charge et nécéssite plusieurs conteneurs : Docker Swarm gère la replication et l’équilibrage des charges
- Une machine hébergeant vos Dockers est en panne : Docker Swarm réplique vos conteneurs sur d’autres machines.
Nous allons donc voir comment configurer ça, et faire un p’tit état des lieux des fonctionnalités proposées.
Créer un cluster Swarm
Pour les tests, j’utiliserai PWD (Play With Docker) pour m’éviter de monter ça sur mon infra :)
Je dispose donc de 4 machines sous Alpine sur lesquelles je vais lancer démarrer un cluster Swarm.
La première étape est de définir un Manager, celui-ci sera la tête du cluster, ainsi que le points d’accès vers les différentes machines. Dans notre cas, on va faire très simple, le manager sera Node1.
Pour lancer le Swarm sur le manager, il suffit d’utiliser la commande docker swarm init.
Mais, si votre système possède un nombre de carte réseau supérieur à 1 (Assez facile sur un serveur), il faut donner l’IP d’écoute.
Dans mon cas, l’IP de l’interface du réseau local (dans lequel les VMs communiquent) est 192.168.0.8.
Donc la commande que je vais lancer est
docker swarm init --advertise-addr 192.168.0.8
Docker me répond ceci :
Swarm initialized: current node (cdbgbq3q4jp1e6espusj48qm3) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5od5zuquln0kgkxpjybvcd45pctp4cp0l12srhdqe178ly8s2m-046hmuczuim8oddmk08gjd1fp 192.168.0.8:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.`
En résumé : Le cluster est bien lancé, et Il nous donne la commande exacte pour rejoindre le cluster depuis d’autres machines !
la Node1 étant le manager, il me suffit d’executer la commande docker swarm join sur les node2-4.
docker swarm join --token SWMTKN-1-5od5zuquln0kgkxpjybvcd45pctp4cp0l12srhdqe178ly8s2m-046hmuczuim8oddmk08gjd1fp 192.168.0.8:2377
Une fois terminé, on peut regarder le résultat sur le manageur avec la commande docker node ls

Déployer un service simple
Si vous êtes adepte de la commande docker run et que vous refusez docker-compose, sachez une chose : je ne vous aime pas.
Comme vous m’êtes sympatique, voici une info qui ne servira pas : l’équivalent de docker run en Swarm est docker service. Mais nous n’allons pas aborder ce sujet dans cet article.
On va plutot utiliser l’équivalent de docker-compose, qui est docker stack.
Donc avant-tout, voici le fichier .yml
version: "3"
services:
viz:
image: dockersamples/visualizer
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
ports:
- "8080:8080"
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
Avant de le démarrer, vous remarquerez surement la partie deploy qui permet de donner des indications à Swarm. On peut donc rajouter des contraintes pour deployer ça sur le/les managers, demander à l’hote de limiter l’utilisation des ressources, ou gérer des répliques pour l’équilibrage des charges.
Ce premier conteneur servira à avoir un dashboard simple pour voir où se positionnent les Dashboard, et éviter de passer uniquement en CLI pour cette fonction.
On va donc déployer ce compose avec la commande suivante:
docker stack deploy --compose-file docker-compose.yml swarm-visualiser
Une fois la commande terminée, il suffit d’ouvrir le serveur web du manager au port 8080.
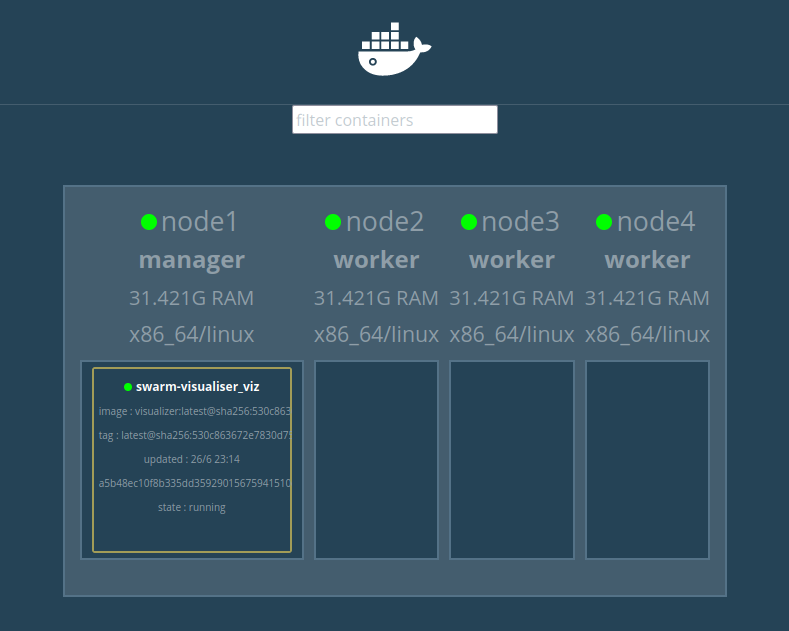
On a donc maintenant un panel Web pour suivre les mises à jour des conteneurs.
Gestion (simplifiée) des replicas
Lorsque l’on accède à un conteneur, on passe obligatoirement par le manager. Mais rien n’empeche d’être rediriger vers le noeud 3-4 en passant par le manager. C’est pourquoi il est possible de répartir la charge (Load Balancing) avec un système similaire à HAProxy, c.a.d. en redirigeant les utilisateurs sur un autre conteneur à chaque chargement d’un page.
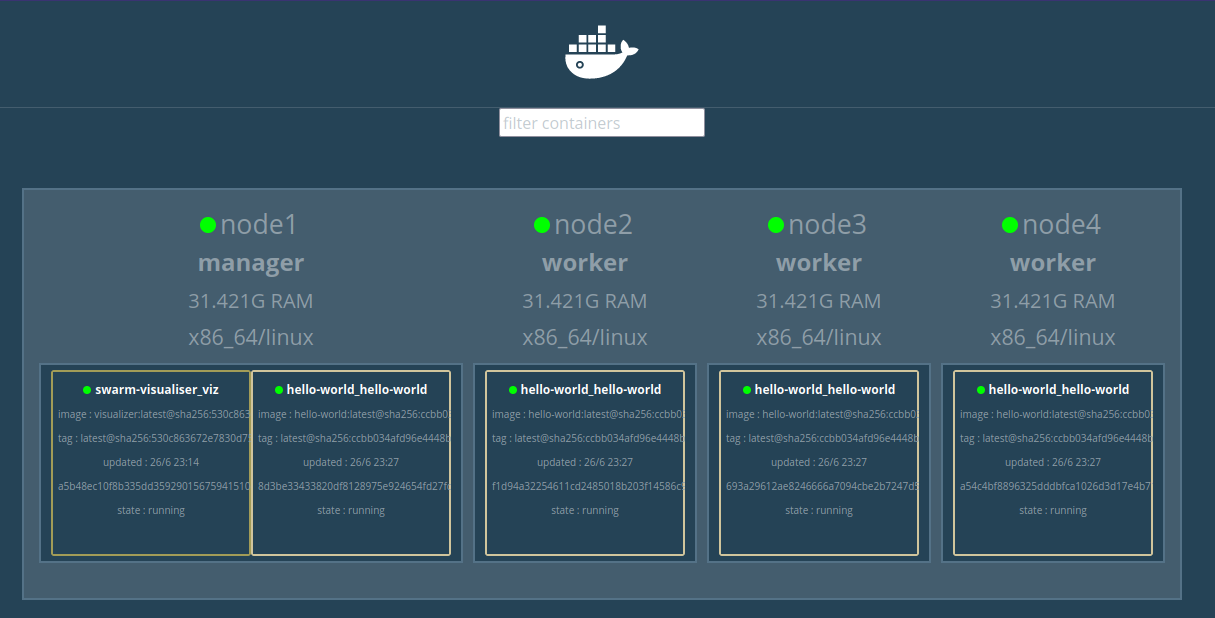
Voici un docker-compose créant automatiquement des replicas :
version: '3.3'
services:
hello-world:
container_name: web-test
ports:
- '80:8000'
image: crccheck/hello-world
deploy:
replicas: 4
Et le résultat est surprenant :
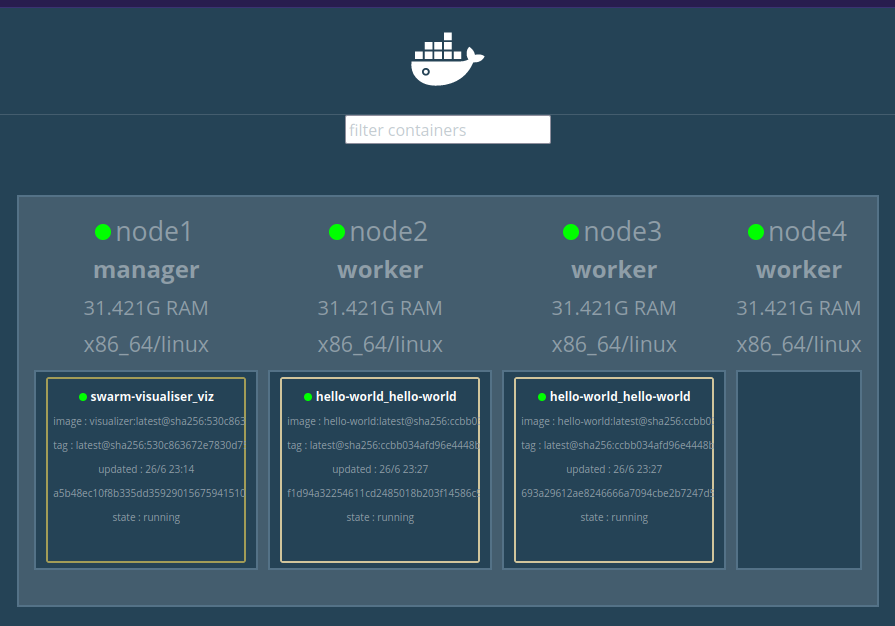
Nous pouvons également adapter le nombre de replica.. En le diminuant:
docker service scale hello-world_hello-world=2
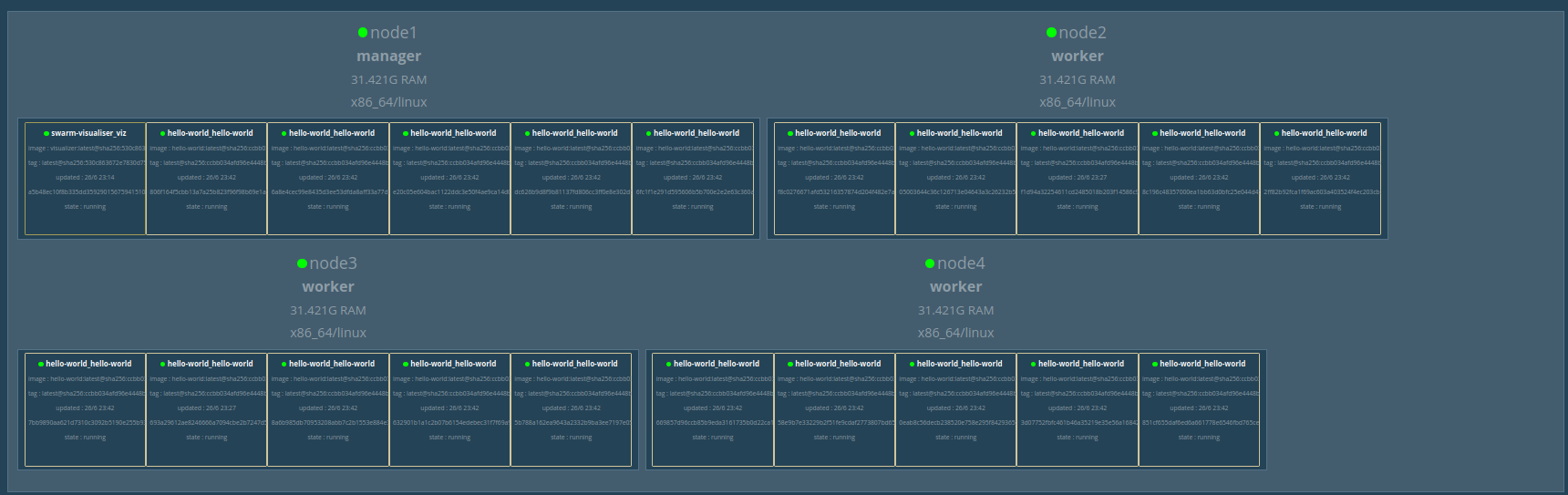
Ou en l’augmentant:
docker service scale hello-world_hello-world=20
Et la Haute-disponibilité, alors?
J’ai axé cet article dans les fonctions de Swarm, et comment les utiliser. Et si je n’ai abordé ce point en priorité, c’est parce que chaque conteneur créé dans ce post est géré en HA !
Je vais, par exemple, stopper de force la 10eme réplique du conteneur “Hello world”, qui se trouve sur Node1. Et Celui-ci sera directement relancé,
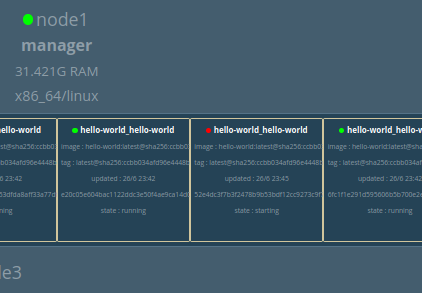
Okay, Mais docker pouvait déjà relancer automatiquement les conteneurs en cas de problème, en quoi swarm est différent?
Et pour répondre à ça, je vais me permettre de stopper le node4
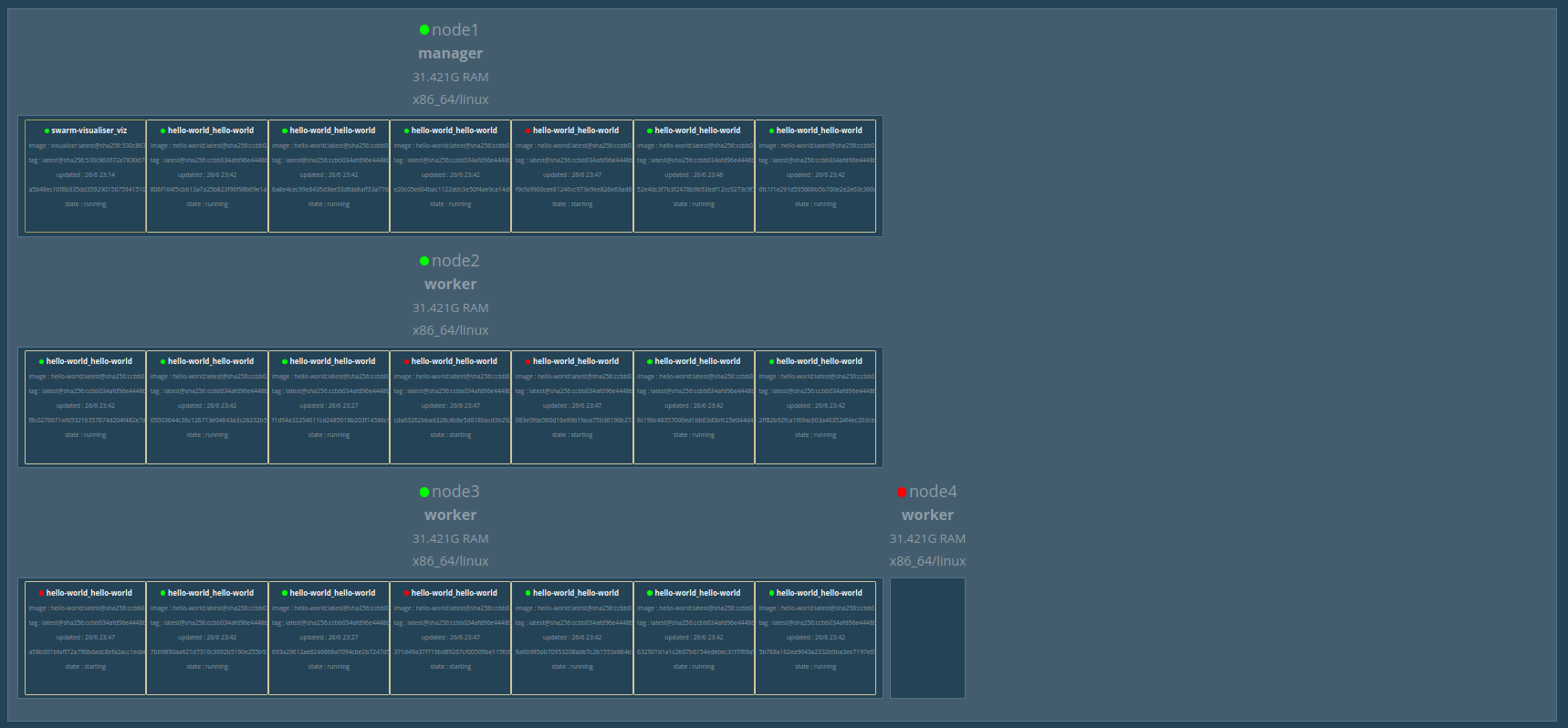
On remarque que les autres noeuds se répartissent automatiquement, (et sans aucune intervention) les conteneurs stoppés. Et comme nous accedons aux services uniquement via les manageurs, ceux-ci ne redirigeront plus que vers les conteneurs démarrés. Un des serveurs peut donc prendre feu, le service sera toujours redondé, équilibré, et accessible.
Conclusion
Docker-Swarm est un point d’entré vers les Clusters d’applications qui sont d’une complexité incroyable sans un outil adapté. Swarm permet facilement de répondre à des besoins particuliers, sans aucune compétence technique. Dans un environnement de production, il est conseillé de s’orienter vers Kubernetes ou Nomad qui sont des alternatives bien plus complètes et puissantes.
Je vous encourage à essayer ce genre de technologie qui gouverneront notre monde de demain !
Merci d’avoir lu