Falco de A à Y

Falco de A à Y
Dès lors qu’on gère un parc de serveurs, il est souvent complexe d’avoir une visibilité sur ce qui s’y passe. Nous ne pouvons jamais vraiment savoir lorsqu’un utilisateur tente d’outrepasser la sécurité de notre système.
Les logs (quand ils existent) sont généralement noyés dans la masse et il est difficile de détecter des comportements anormaux qui pourraient être le signe d’une intrusion.
L’usage d’un concentrateur de logs comme Loki ou Elasticsearch se révèle être une solution efficace pour centraliser les logs et les rendre plus facilement exploitables. Mais cela ne suffit pas pour détecter des actions dangereuses comme la création d’un reverse shell, l’écriture dans un répertoire sensible, la recherche de clés SSH… qui n’écrivent pas de logs.
En dehors des attaques sur les services exposés (les VPN, les serveurs web, les daemons SSH, etc.), nous sommes complètement aveugles sur ce qui se passe sur nos serveurs. Si un acteur malveillant s’introduit via une clé SSH compromise, il peut se déplacer librement et il sera très difficile de le détecter (SELinux et AppArmor bloquent néanmoins certaines tentatives). C’est là que Falco intervient.
Qu’est-ce que Falco ?
Falco est un moteur de détection de menaces dans vos systèmes. Il est particulièrement adapté pour les environnements conteneurisés (Docker, Kubernetes) mais ne se limite pas à ceux-ci.
Celui-ci fonctionne en surveillant les appels systèmes et en les comparant à des règles prédéfinies. Dès qu’un événement anormal est détecté, Falco envoie une alerte. Ces règles sont écrites en YAML et peuvent être affinées pour correspondre à votre environnement.
Dans cet article, nous allons voir ce qu’est Falco afin d’être alertés en cas d’événements anormaux sur nos serveurs ainsi que comment le mettre en place dans un environnement Kubernetes.
À savoir que Falco est un projet accepté par la CNCF (Cloud Native Computing Foundation) dans la catégorie des projets graduated (au même niveau que Cilium, Rook, ArgoCD ou Prometheus).
C’est parti pour découvrir Falco de A à Y… avec une bonne tasse de café ! (le Z n’étant pas atteignable pour un logiciel en constante évolution).
Installation sur un serveur Debian 12
Commençons par installer Falco sur un serveur Debian 12. Pour cela, nous allons passer par un dépôt APT officiel.
curl -fsSL https://falco.org/repo/falcosecurity-packages.asc | \
sudo gpg --dearmor -o /usr/share/keyrings/falco-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/falco-archive-keyring.gpg] https://download.falco.org/packages/deb stable main" | sudo tee /etc/apt/sources.list.d/falcosecurity.list
sudo apt-get update && sudo apt-get install -y falco
Durant l’installation, il vous sera demandé de choisir un “driver”. Cela désigne la manière dont Falco va surveiller les appels systèmes et les événements. Il est possible de choisir entre :
- Kernel module (Legacy)
- eBPF
- Modern eBPF
Le Kernel module est à éviter, il est beaucoup moins performant que l’eBPF et n’apporte aucune fonctionnalité supplémentaire. La différence entre l’eBPF et le Modern eBPF est son implémentation. En effet, l’eBPF classique nécessite que Falco télécharge une librairie contenant les instructions qu’il irait compiler à la volée dans notre kernel. Cette librairie est spécifique à la version du kernel que nous utilisons, nous obligeant à re-télécharger cette dernière à chaque mise à jour du kernel. Le module Modern eBPF est différent, car suivant le paradigme de la BPF CO-RE (BPF Compile Once, Run Everywhere). Le code à injecter dans le kernel est déjà présent dans le binaire de Falco et aucun driver externe n’est nécessaire (en revanche, il nécessite un kernel 5.8 minimum, là où l’eBPF classique fonctionne à partir du kernel 4.14).
Ma machine possède un kernel 6.1.0, je vais donc choisir Modern eBPF.
Suite à ça, je vérifie que Falco est bien installé avec la commande falco --version.
$ falco --version
Thu Apr 04 10:29:22 2024: Falco version: 0.37.1 (x86_64)
Thu Apr 04 10:29:22 2024: Falco initialized with configuration file: /etc/falco/falco.yaml
Thu Apr 04 10:29:22 2024: System info: Linux version 6.1.0-16-amd64 (debian-kernel@lists.debian.org) (gcc-12 (Debian 12.2.0-14) 12.2.0, GNU ld (GNU Binutils for Debian) 2.40) #1 SMP PREEMPT_DYNAMIC Debian 6.1.67-1 (2023-12-12)
{"default_driver_version":"7.0.0+driver","driver_api_version":"8.0.0","driver_schema_version":"2.0.0","engine_version":"31","engine_version_semver":"0.31.0","falco_version":"0.37.1","libs_version":"0.14.3","plugin_api_version":"3.2.0"}
Je peux alors démarrer le service Falco correspondant à mon driver (dans mon cas falco-bpf.service, les autres services étant falco-kmod.service et falco-bpf.service).
$ systemctl status falco-modern-bpf.service
● falco-modern-bpf.service - Falco: Container Native Runtime Security with modern ebpf
Loaded: loaded (/lib/systemd/system/falco-modern-bpf.service; enabled; preset: enabled)
Active: active (running) since Thu 2024-04-04 10:31:07 CEST; 44s ago
Docs: https://falco.org/docs/
Main PID: 2511 (falco)
Tasks: 9 (limit: 3509)
Memory: 32.8M
CPU: 828ms
CGroup: /system.slice/falco-modern-bpf.service
└─2511 /usr/bin/falco -o engine.kind=modern_ebpf
avril 04 10:31:07 falco-linux falco[2511]: Falco initialized with configuration file: /etc/falco/falco.yaml
avril 04 10:31:07 falco-linux falco[2511]: System info: Linux version 6.1.0-16-amd64 (debian-kernel@lists.debian.org) (gcc-12 (Debian 12.2.0-14) 12.2.0, GNU ld (GNU Binutils for Debian) 2.4>
avril 04 10:31:07 falco-linux falco[2511]: Loading rules from file /etc/falco/falco_rules.yaml
avril 04 10:31:07 falco-linux falco[2511]: Loading rules from file /etc/falco/falco_rules.local.yaml
avril 04 10:31:07 falco-linux falco[2511]: The chosen syscall buffer dimension is: 8388608 bytes (8 MBs)
avril 04 10:31:07 falco-linux falco[2511]: Starting health webserver with threadiness 4, listening on 0.0.0.0:8765
avril 04 10:31:07 falco-linux falco[2511]: Loaded event sources: syscall
avril 04 10:31:07 falco-linux falco[2511]: Enabled event sources: syscall
avril 04 10:31:07 falco-linux falco[2511]: Opening 'syscall' source with modern BPF probe.
avril 04 10:31:07 falco-linux falco[2511]: One ring buffer every '2' CPUs.
Nous reparlerons de la configuration des drivers un peu plus tard dans un prochain chapitre
Créer une première règle Falco
Pour les impatients, voici une première règle Falco qui permet de détecter les écritures dans les répertoires binaires qui ne sont pas provoquées par les gestionnaires de paquets.
Par défaut, les règles sont présentes dans les fichiers :
/etc/falco/falco_rules.yaml→ Règles par défaut/etc/falco/falco_rules.local.yaml→ Règles personnalisées/etc/falco/rules.d/*→ Règles personnalisées par dépôt de fichier
Nous allons donc créer notre première règle dans /etc/falco/falco_rules.local.yaml.
- macro: bin_dir
condition: (fd.directory in (/bin, /sbin, /usr/bin, /usr/sbin))
- list: package_mgmt_binaries
items: [rpm_binaries, deb_binaries, update-alternat, gem, npm, python_package_managers, sane-utils.post, alternatives, chef-client, apk, snapd]
- macro: package_mgmt_procs
condition: (proc.name in (package_mgmt_binaries))
- rule: Write below binary dir
desc: >
Trying to write to any file below specific binary directories can serve as an auditing rule to track general system changes.
Such rules can be noisy and challenging to interpret, particularly if your system frequently undergoes updates. However, careful
profiling of your environment can transform this rule into an effective rule for detecting unusual behavior associated with system
changes, including compliance-related cases.
condition: >
open_write and evt.dir=<
and bin_dir
and not package_mgmt_procs
output: File below a known binary directory opened for writing (file=%fd.name pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty %container.info)
priority: ERROR
Nous verrons un peu plus tard comment se compose une règle, mais pour l’instant, nous admettons seulement que cette règle permet de détecter les écritures dans les répertoires binaires qui ne sont pas provoquées par les gestionnaires de paquets.
Après avoir créé notre règle dans le fichier /etc/falco/falco_rules.local.yaml, Falco devrait recharger automatiquement la règle (si ce n’est pas le cas, nous pouvons le faire manuellement via sudo systemctl reload falco-modern-bpf.service).
Essayons maintenant de déclencher l’alerte que nous venons de créer. Je vais ouvrir un premier terminal affichant les logs de Falco avec journalctl -u falco-modern-bpf.service -f et dans un second exécuter la commande touch /bin/toto.
avril 04 11:18:38 falco-linux falco[2511]: 11:18:38.057651538: Error File below a known binary directory opened for writing (file=/bin/toto pcmdline=bash gparent=sshd evt_type=openat user=root user_uid=0 user_loginuid=0 process=touch proc_exepath=/usr/bin/touch parent=bash command=touch /bin/toto terminal=34816 container_id=host container_name=host)
Victoire, nous avons déclenché une alerte ! 🥳
Maintenant, elle ne devrait pas se déclencher si j’installe un paquet via apt :
$ apt install -y apache2
$ which apache2
/usr/sbin/apache2
Le binaire d’apache2 est dans /usr/sbin (dossier bien surveillé par notre règle Falco), mais aucune alerte ne s’est déclenchée.
On commence déjà à comprendre comment fonctionne Falco. Nous allons pouvoir aller un peu plus dans le détail.
Architecture de Falco
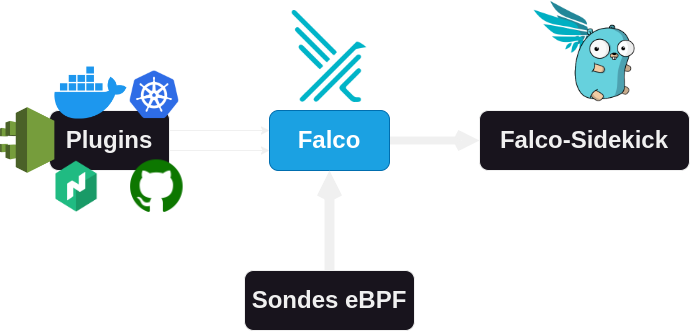
Nativement, Falco est fait pour fonctionner à partir de sondes eBPF (Extended Berkeley Packet Filter). Ces sondes sont des programmes qui sont chargées directement dans le kernel pour prévenir Falco (coté user-land) de ce qui se passe. Il est aussi possible de lancer Falco à partir d’un module ajouté au kernel.
Information
Qu’est-ce que l’eBPF ?
L’eBPF, pour extended Berkeley Packet Filter, est une technologie permettant d’exécuter des programmes dans un environnement sandbox au sein du noyau Linux et ce sans avoir besoin de changer le code du noyau ou de charger des modules externes. L’eBPF est disponible depuis le kernel 3.18 (2014) et possède la capacité de se greffer à un évènement. De cette manière, le code injecté n’est appelé que lorsqu’un appel système lié à notre besoin est exécuté. Cela permet de ne pas surcharger le kernel avec des programmes inutiles.
Pour en savoir plus, je vous invite à regarder la vidéo de Laurent GRONDIN.

Les appels systèmes
Falco est un agent qui surveille les appels systèmes à l’aide de l’eBPF ou d’un module kernel (lorsque l’eBPF n’est pas possible). Les programmes font théoriquement tous des appels systèmes pour interagir avec le kernel (indispensable pour lire/écrire un fichier, faire une requête, etc.).
Pour voir les appels systèmes d’un processus, on peut utiliser la commande strace. Celle-ci permet de lancer un programme et de voir les appels systèmes qui sont réalisés.
$ strace echo "P'tit kawa?"
execve("/usr/bin/echo", ["echo", "P'tit kawa?"], 0x7fff2442be98 /* 66 vars */) = 0
brk(NULL) = 0x629292ad2000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fff1aa14580) = -1 EINVAL (Argument invalide)
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7604dfe2e000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (Aucun fichier ou dossier de ce nom)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=110843, ...}, AT_EMPTY_PATH) = 0
mmap(NULL, 110843, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7604dfe12000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\237\2\0\0\0\0\0"..., 832) = 832
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
pread64(3, "\4\0\0\0 \0\0\0\5\0\0\0GNU\0\2\0\0\300\4\0\0\0\3\0\0\0\0\0\0\0"..., 48, 848) = 48
pread64(3, "\4\0\0\0\24\0\0\0\3\0\0\0GNU\0\302\211\332Pq\2439\235\350\223\322\257\201\326\243\f"..., 68, 896) = 68
newfstatat(3, "", {st_mode=S_IFREG|0755, st_size=2220400, ...}, AT_EMPTY_PATH) = 0
pread64(3, "\6\0\0\0\4\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0@\0\0\0\0\0\0\0"..., 784, 64) = 784
mmap(NULL, 2264656, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7604dfa00000
mprotect(0x7604dfa28000, 2023424, PROT_NONE) = 0
mmap(0x7604dfa28000, 1658880, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x28000) = 0x7604dfa28000
mmap(0x7604dfbbd000, 360448, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1bd000) = 0x7604dfbbd000
mmap(0x7604dfc16000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x215000) = 0x7604dfc16000
mmap(0x7604dfc1c000, 52816, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7604dfc1c000
close(3) = 0
mmap(NULL, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7604dfe0f000
arch_prctl(ARCH_SET_FS, 0x7604dfe0f740) = 0
set_tid_address(0x7604dfe0fa10) = 12767
set_robust_list(0x7604dfe0fa20, 24) = 0
rseq(0x7604dfe100e0, 0x20, 0, 0x53053053) = 0
mprotect(0x7604dfc16000, 16384, PROT_READ) = 0
mprotect(0x6292924c8000, 4096, PROT_READ) = 0
mprotect(0x7604dfe68000, 8192, PROT_READ) = 0
prlimit64(0, RLIMIT_STACK, NULL, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
munmap(0x7604dfe12000, 110843) = 0
getrandom("\xe1\x15\x54\xd3\xf5\xa1\x30\x4d", 8, GRND_NONBLOCK) = 8
brk(NULL) = 0x629292ad2000
brk(0x629292af3000) = 0x629292af3000
openat(AT_FDCWD, "/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
newfstatat(3, "", {st_mode=S_IFREG|0644, st_size=15751120, ...}, AT_EMPTY_PATH) = 0
mmap(NULL, 15751120, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7604dea00000
close(3) = 0
newfstatat(1, "", {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x3), ...}, AT_EMPTY_PATH) = 0
write(1, "P'tit kawa?\n", 12P'tit kawa?
) = 12
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
Ce sont justement ces appels systèmes que Falco va surveiller pour détecter les potentielles anomalies.
Mais pourquoi ne pas se contenter de
straceet ainsi ne pas avoir à passer par l’eBPF ?
strace n’est pas une solution viable pour plusieurs raisons et notamment parce qu’il ne peut pas surveiller plusieurs processus en même temps. De plus, il fonctionne à l’envers de ce que nous souhaitons faire : il nous permet de voir les appels systèmes d’un processus surveillé, mais pas de réagir aux appels systèmes pour alerter d’un processus malveillant.
Sysdig (l’entreprise derrière Falco) propose aussi un outil éponyme pour visualiser et enregistrer les appels systèmes dans un fichier afin de faciliter la création de règles Falco.
VERSION="0.36.0"
wget https://github.com/draios/sysdig/releases/download/${VERSION}/sysdig-${VERSION}-x86_64.deb
dpkg -i sysdig-${VERSION}-x86_64.deb
Je fixe la version à 0.36.0, pour que vous ayez les mêmes résultats que moi. Mais je vous invite bien sûr à utiliser la dernière version disponible.
À l’aide de la commande sysdig proc.name=chmod on visualise les appels systèmes liés à cette commande.
153642 15:18:57.468174047 1 chmod (72012.72012) < execve res=0 exe=chmod args=777.README.md. tid=72012(chmod) pid=72012(chmod) ptid=71438(bash) cwd=<NA> fdlimit=1024 pgft_maj=0 pgft_min=33 vm_size=432 vm_rss=4 vm_swap=0 comm=chmod cgroups=cpuset=/user.slice.cpu=/user.slice/user-0.slice/session-106.scope.cpuacct=/.i... env=SHELL=/bin/bash.LESS= -R.PWD=/root.LOGNAME=root.XDG_SESSION_TYPE=tty.LS_OPTIO... tty=34823 pgid=72012(chmod) loginuid=0(root) flags=1(EXE_WRITABLE) cap_inheritable=0 cap_permitted=1FFFFFFFFFF cap_effective=1FFFFFFFFFF exe_ino=654358 exe_ino_ctime=2023-12-29 16:08:00.974303000 exe_ino_mtime=2022-09-20 17:27:27.000000000 uid=0(root) trusted_exepath=/usr/bin/chmod
153643 15:18:57.468204086 1 chmod (72012.72012) > brk addr=0
153644 15:18:57.468205471 1 chmod (72012.72012) < brk res=55B917192000 vm_size=432 vm_rss=4 vm_swap=0
153645 15:18:57.468270944 1 chmod (72012.72012) > mmap addr=0 length=8192 prot=3(PROT_READ|PROT_WRITE) flags=10(MAP_PRIVATE|MAP_ANONYMOUS) fd=-1(EPERM) offset=0
Nous réutiliserons cet outil dans un prochain chapitre pour créer des règles Falco.
Être alerté en cas d’événement
C’est bien beau d’être au courant d’une intrusion, mais si personne n’est là pour réagir cela ne sert pas à grand-chose !
C’est pourquoi nous allons installer une seconde application : Falco Sidekick.
Son rôle est de recevoir les alertes de Falco et de les rediriger vers des outils externes (Mail, Alertmanager, Slack, etc.). Pour l’installer, nous pouvons directement télécharger le binaire et créer un service systemd (dans l’idéal, il faudrait la déployer dans une machine isolée pour éviter qu’un attaquant ne la désactive).
VER="2.28.0"
wget -c https://github.com/falcosecurity/falcosidekick/releases/download/${VER}/falcosidekick_${VER}_linux_amd64.tar.gz -O - | tar -xz
chmod +x falcosidekick
sudo mv falcosidekick /usr/local/bin/
sudo touch /etc/systemd/system/falcosidekick.service
sudo chmod 664 /etc/systemd/system/falcosidekick.service
On édite le fichier /etc/systemd/system/falcosidekick.service pour y ajouter le contenu suivant :
[Unit]
Description=Falcosidekick
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
Restart=always
RestartSec=1
ExecStart=/usr/local/bin/falcosidekick -c /etc/falcosidekick/config.yaml
[Install]
WantedBy=multi-user.target
Mais avant de le lancer, nous avons besoin de créer le fichier de configuration /etc/falcosidekick/config.yaml.
Je gère mes alertes avec Alertmanager et je souhaite continuer à l’utiliser pour les alertes de Falco car il me permet de router les notifications vers Gotify ou Email en fonction de leur priorité.
debug: false
alertmanager:
hostport: "http://192.168.1.89:9093"
Pour démarrer le service, nous pouvons passer par systemctl.
systemctl daemon-reload
systemctl enable --now falcosidekick
Maintenant, nous devons demander à notre agent Falco de se connecter à notre Falco-Sidekick. Pour cela, j’édite la configuration dans /etc/falco/falco.yaml pour activer l’output http vers Falco-Sidekick.
Voici les valeurs à éditer :
json_output: true
json_include_output_property: true
http_output:
enabled: true
url: http://192.168.1.105:2801/ # IP:port de Falco-Sidekick
Je redémarre Falco-Sidekick et je crée une première alerte de test :
curl -sI -XPOST http://192.168.1.105:2801/test
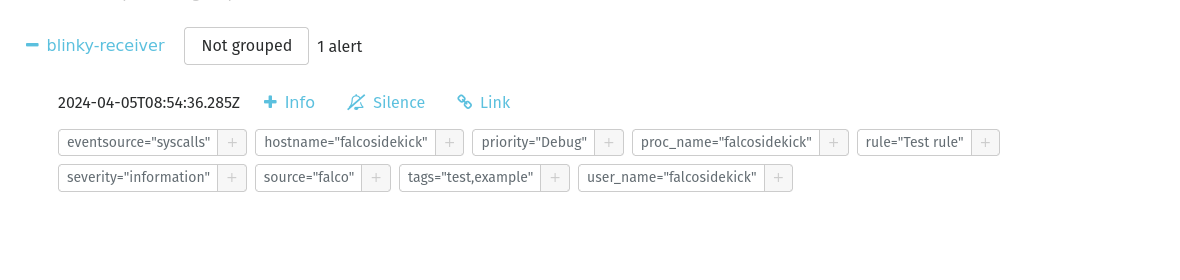
Je reçois bien cette alerte de test sur mon alertmanager et même par mail (grâce à l’intégration d’un SMTP dans mon alertmanager) :
À présent, essayons de déclencher l’alerte de la règle Write below binary dir que nous avons créée plus tôt.

Le touch /bin/coffee est bien signalé directement à mon Alertmanager !
On visualise également des détails comme le processus ayant initié l’appel système, touch (bash ayant créé ce processus, lui-même appelé par tmux).
Pour monitorer Falco-Sidekick, vous pouvez utiliser les endpoints suivants :
/ping- Renvoie “pong” en clair/healthz- Renvoie{ 'status': 'ok' }/metrics- Exporter prometheus
Interface Web pour Falco
Avoir couplé Falco-Sidekick avec AlertManager pour être notifié en cas d’incident est une bonne chose, mais si on souhaite faire plus simple et avoir une interface web pour consulter les alertes, il est possible d’utiliser Falcosidekick UI.
Falco-Sidekick UI est une interface web qui va récupérer les alertes de Falco-Sidekick. Celui-ci est basé sur une base de données Redis qui va stocker les alertes pour les restituer dans un tableau de bord.
Nous pouvons l’installer avec des conteneurs Docker de la façon suivante :
version: '3'
services:
falco-sidekick-ui:
image: falcosecurity/falcosidekick-ui:2.3.0-rc2
restart: always
ports:
- "2802:2802"
environment:
- FALCOSIDEKICK_UI_REDIS_URL=redis:6379
- FALCOSIDEKICK_UI_USER=weare:coffeelovers
depends_on:
- redis
redis:
image: redis/redis-stack:7.2.0-v9
Une fois les images téléchargées, nous pouvons démarrer les conteneurs avec docker-compose up -d et s’authentifier sur l’interface web avec les identifiants weare:coffeelovers.
Je dois ensuite demander à Falco-Sidekick de router les alertes vers Falco-Sidekick UI. Pour cela, j’édite mon fichier de configuration /etc/falcosidekick/config.yaml :
debug: false
alertmanager:
hostport: "http://192.168.1.89:9093"
webui:
url: "http://192.168.1.105:2802"
Avec cette nouvelle configuration, l’interface web et AlertManager reçoivent les événements.
Après quelques alertes déclenchées, mon interface se remplit un peu.
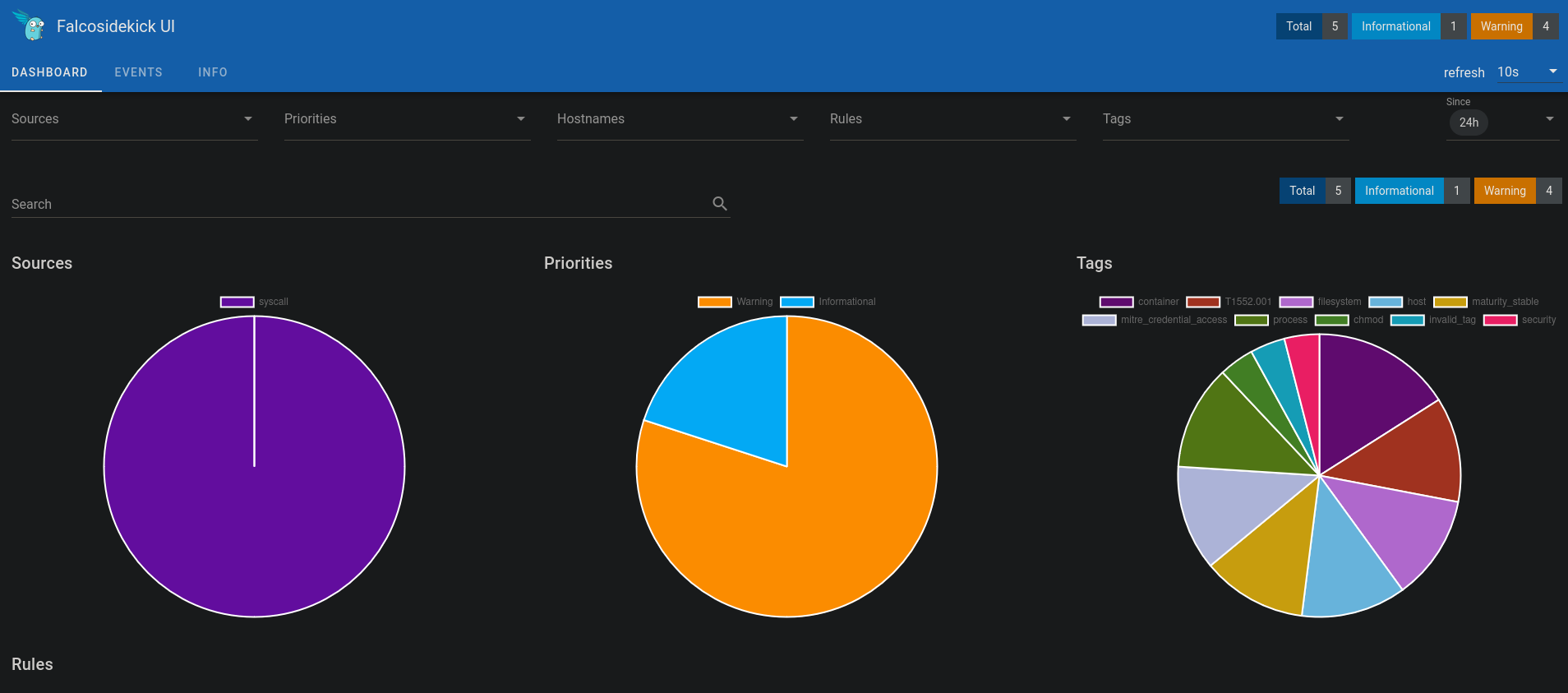
Il m’est alors possible de trier les alertes par type, règle, priorité, etc.
Je peux ainsi revenir sur des alertes précédentes pour y constater des récurrences sur les machines surveillées.
Information
Dans le cas actuel, il n’y a aucune persistance des données dans la base Redis. Si vous redémarrez le conteneur, vous perdrez toutes les alertes précédentes. Si Falco-Sidekick UI est utilisé en production, il convient de mettre en place une base de données persistante.
Maintenant que nous avons le nécessaire pour visualiser les alertes, nous allons voir comment créer des règles Falco.
Règles Falco
Une règle Falco est composée de plusieurs éléments : un nom, une description, une condition, une sortie (output), une priorité et des tags.
Voici un exemple de règle Falco :
- rule: Program run with disallowed http proxy env
desc: >
Detect curl or wget usage with HTTP_PROXY environment variable. Attackers can manipulate the HTTP_PROXY variable's
value to redirect application's internal HTTP requests. This could expose sensitive information like authentication
keys and private data.
condition: >
spawned_process
and (proc.name in (http_proxy_binaries))
and ( proc.env icontains HTTP_PROXY OR proc.env icontains HTTPS_PROXY )
output: Curl or wget run with disallowed HTTP_PROXY environment variable (env=%proc.env evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty exe_flags=%evt.arg.flags %container.info)
priority: NOTICE
tags: [maturity_incubating, host, container, users, mitre_execution, T1204]
Le nom, la description, les tags et la priorité seront affichés dans le signalement d’un événement suspect. Il convient de soigner le contenu de ces champs pour faciliter la lecture des alertes depuis un outil externe.
Si la mention proc.env icontains HTTP_PROXY est plutôt facile à comprendre. Qu’en est-il de spawned_process ou http_proxy_binaries ?
Commençons d’abord par expliquer les champs que nous utilisons pour contextualiser une alerte.
Les champs (fields)
Les champs sont les variables utilisées dans les règles Falco. Elles diffèrent en fonction de l’événement (l’appel système) que nous souhaitons surveiller. Il existe plusieurs classes de champs, par exemple :
evt: Les informations génériques de l’événement (evt.time,evt.type,evt.dir).proc: Les informations du processus (proc.name,proc.cmdline,proc.tty).user/group: Les informations de l’utilisateur qui a déclenché l’événement (user.name,group.gid).fd: Les informations sur les fichiers ouverts et les connexions (fd.ip,fd.name).container: Les informations sur le conteneur Docker ou pod Kubernetes (container.id,container.name,container.image).k8s: Les informations sur les objets Kubernetes (k8s.ns.name,k8s.pod.name).
La définition d’un champ à surveiller commence toujours par un appel système (commençant par evt) avant de se contextualiser avec d’autres champs (comme le nom du processus, l’utilisateur l’ayant exécuté ou le fichier ouvert).
Pour voir la liste complète des champs, vous pouvez consulter la documentation officielle ou directement avec la commande falco --list=syscall.
Opérateurs
Les conditions peuvent être utilisées dans les règles Falco.
| Opérateurs | Description |
|---|---|
=, != | Opérateurs d’égalité et d’inégalité. |
<=, <, >=, > | Opérateurs de comparaison pour les valeurs numériques. |
contains, icontains | Pour les chaînes de caractères, renvoie “vrai” si une chaîne en contient une autre, et icontains est la version insensible à la casse. Pour les drapeaux, renvoie “vrai” si le drapeau est défini. Exemples : proc.cmdline contains "-jar", evt.arg.flags contains O_TRUNC. |
dwith, endswith | Vérifie le préfixe ou le suffixe des chaînes de caractères. |
glob | Évalue les motifs glob standard. Exemple : fd.name glob "/home/*/.ssh/*". |
in | Évalue si l’ensemble fourni (pouvant avoir un seul élément) est entièrement contenu dans un autre ensemble. Exemple : (b,c,d) in (a,b,c) renvoie FAUX puisque d n’est pas contenu dans l’ensemble comparé (a,b,c). |
intersects | Évalue si l’ensemble fourni (pouvant avoir un seul élément) a au moins un élément en commun avec un autre ensemble. Exemple : (b,c,d) intersects (a,b,c) renvoie VRAI puisque les deux ensembles contiennent b et c. |
pmatch | (Prefix Match) Compare un chemin de fichier à un ensemble de préfixes de fichiers ou de répertoires. Exemple : fd.name pmatch (/tmp/hello) renvoie vrai contre /tmp/hello, /tmp/hello/world mais pas contre /tmp/hello_world. |
exists | Vérifie si un champ est défini. Exemple : k8s.pod.name exists. |
bcontains, bstartswith | (Binary contains) Ces opérateurs fonctionnent de manière similaire à contains et startswith et permettent d’effectuer une correspondance d’octets contre une chaîne brute d’octets, en acceptant comme entrée une chaîne hexadécimale. Exemples : evt.buffer bcontains CAFE, evt.buffer bstartswith CAFE_. |
Ainsi, pour comparer le nom du processus, on peut utiliser les conditions suivantes : proc.name = sshd ou proc.name contains sshd.
Lorsqu’une partie de la condition ne possède pas d’opérateur, cela signifie que c’est une macro, voyons de quoi il s’agit.
Les macros et les listes
Les macros sont des “variables” qui peuvent être utilisées dans les règles Falco pour faciliter la lecture et la maintenance des règles ou encore pour réutiliser des conditions fréquemment employées.
Par exemple, plutôt que de répéter la condition proc.name in (rpm, dpkg, apt, yum) dans les 10 règles qui la possèdent, nous pouvons créer une macro package_mgmt_procs ainsi qu’une liste package_mgmt_binaries qui contient les noms des processus de gestion de paquets.
- list: package_mgmt_binaries
items: [rpm_binaries, deb_binaries, update-alternat, gem, npm, python_package_managers, sane-utils.post, alternatives, chef-client, apk, snapd]
- macro: package_mgmt_procs
condition: (proc.name in (package_mgmt_binaries))
Ainsi, dans la règle suivante, nous pouvons simplement utiliser package_mgmt_procs pour vérifier si le processus est un gestionnaire de paquets. Celle-ci renverra vrai si le processus en est effectivement un.
- rule: Write below binary dir
desc: >
Trying to write to any file below specific binary directories can serve as an auditing rule to track general system changes.
Such rules can be noisy and challenging to interpret, particularly if your system frequently undergoes updates. However, careful
profiling of your environment can transform this rule into an effective rule for detecting unusual behavior associated with system
changes, including compliance-related cases.
condition: >
open_write and evt.dir=<
and bin_dir
and not package_mgmt_procs
output: File below a known binary directory opened for writing (file=%fd.name pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty %container.info)
priority: ERROR
On obtient une règle très simple à lire avec du code réutilisable dans d’autres contextes.
La règle ci-dessus provient de la documentation officielle de Falco. Mais en connaissant les champs et les opérateurs, nous pouvons aisément créer nos propres règles.
Dans l’exemple ci-après, je souhaite détecter si un utilisateur essaie de rechercher des fichiers sensibles (comme des clés SSH ou des fichiers de configuration Kubernetes).
- list: searching_binaries
items: ['grep', 'fgrep', 'egrep', 'rgrep', 'locate', 'find']
- rule: search for sensitives files
desc: Detect if someone is searching for a sensitive file
condition: >
spawned_process and proc.name in (searching_binaries) and
(
proc.args contains "id_rsa" or
proc.args contains "id_ed25519" or
proc.args contains "kube/config"
)
output: Someone is searching for a sensitive file (file=%proc.args pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty)
priority: INFO
tags: [sensitive_data, ssh]
Écrire une règle
Pour écrire une règle comme nous l’avons fait juste avant (search for sensitives files), il est possible de le faire à l’aveugle comme nous l’avons fait (en écrivant, puis testant), mais les mainteneurs de Falco proposent plutôt de passer par sysdig. Nous allons voir l’intérêt de cette méthode.
Sysdig propose une fonctionnalité pour enregistrer les appels systèmes dans un fichier et utiliser cet enregistrement avec la même syntaxe des règles Falco pour voir si un événement est bien détecté.
Avant de commencer, il convient de savoir à quel événement nous souhaitons réagir. Pour cela, certains manpages peuvent nous aider à connaitre quels appels systèmes sont utilisés par un programme.
Dans un premier terminal, nous allons démarrer l’enregistrement des appels systèmes dans un fichier.
Je vais faire l’action que je souhaite surveiller (dans mon cas, je veux prévenir d’un chmod 777). Dans la page man de chmod (man 2 chmod), je vois que l’appel système utilisé est fchmodat et fchmod.
Je vais donc enregistrer les appels systèmes fchmodat, fchmod et chmod dans un fichier dumpfile.scap.
sysdig -w dumpfile.scap "evt.type in (fchmod,chmod,fchmodat)"
Dans un second terminal, je vais exécuter la commande chmod 777 /tmp/test.
chmod 777 /tmp/test
J’arrête l’enregistrement des appels systèmes avec Ctrl+C. Je peux utiliser sysdig pour lire ce fichier et voir les appels systèmes qui y ont été enregistrés.
$ sysdig -r dumpfile.scap
1546 16:21:59.800433848 1 <NA> (-1.76565) > fchmodat
1547 16:21:59.800449701 1 <NA> (-1.76565) < fchmodat res=0 dirfd=-100(AT_FDCWD) filename=/tmp/test mode=0777(S_IXOTH|S_IWOTH|S_IROTH|S_IXGRP|S_IWGRP|S_IRGRP|S_IXUSR|S_IWUSR|S_IRUSR)
Notre chmod a bien été enregistré.
Je peux maintenant rejouer cet enregistrement en rajoutant des conditions pour créer ma règle Falco réagissant à cet évènement. Après quelques tests, j’arrive à la règle suivante :
$ sysdig -r ~/dumpfile.scap "evt.type in (fchmod,chmod,fchmodat) and (evt.arg.mode contains S_IXOTH and evt.arg.mode contains S_IWOTH and evt.arg.mode contains S_IROTH and evt.arg.mode contains S_IXGRP and evt.arg.mode contains S_IWGRP and evt.arg.mode contains S_IRGRP and evt.arg.mode contains S_IXUSR and evt.arg.mode contains S_IWUSR and evt.arg.mode contains S_IRUSR)"
1547 16:21:59.800449701 1 <NA> (-1.76565) < fchmodat res=0 dirfd=-100(AT_FDCWD) filename=/tmp/test mode=0777(S_IXOTH|S_IWOTH|S_IROTH|S_IXGRP|S_IWGRP|S_IRGRP|S_IXUSR|S_IWUSR|S_IRUSR)
Il ne me reste plus qu’à créer la règle Falco à partir de ma commande sysdig.
- macro: chmod_777
condition: (evt.arg.mode contains S_IXOTH and evt.arg.mode contains S_IWOTH and evt.arg.mode contains S_IROTH and evt.arg.mode contains S_IXGRP and evt.arg.mode contains S_IWGRP and evt.arg.mode contains S_IRGRP and evt.arg.mode contains S_IXUSR and evt.arg.mode contains S_IWUSR and evt.arg.mode contains S_IRUSR)
- rule: chmod 777
desc: Detect if someone is trying to chmod 777 a file
condition: >
evt.type in (fchmod,chmod,fchmodat) and chmod_777
output: Someone is trying to chmod 777 a file (file=%fd.name pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty)
priority: NOTICE
tags: [chmod, security]
Override et exceptions
Un cas complexe à gérer est celui des exceptions. Par exemple, je découvre qu’un utilisateur spécifique a besoin de chercher des fichiers sensibles dans un script de maintenance.
La règle search for sensitives files va réagir à tous les processus find cherchant des clés SSH. Or, je veux que mon utilisateur puisse le faire sans déclencher une alerte.
- list: searching_binaries
items: ['grep', 'fgrep', 'egrep', 'rgrep', 'locate', 'find']
- rule: search for sensitives files
desc: Detect if someone is searching for a sensitive file
condition: >
spawned_process and proc.name in (searching_binaries) and
(
proc.args contains "id_rsa" or
proc.args contains "id_ed25519" or
proc.args contains "kube/config"
)
output: Someone is searching for a sensitive file (file=%proc.args pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty)
priority: INFO
tags: [sensitive_data, ssh]
Il m’est possible de le faire de deux façons :
- Ajouter un patch dans la règle search for sensitives files pour ajouter une condition supplémentaire.
- Ajouter une exception dans la règle search for sensitives files pour ignorer les alertes pour un utilisateur spécifique.
Pourquoi ne pas modifier la condition pour exclure ce cas ?
Je dispose de X machines possédant les mêmes règles Falco (nous verrons comment synchroniser les règles sur les machines plus bas), je veux avoir le moins de différences possibles entre les machines. Je préfère alors ajouter un fichier patch qui sera exclusif à cette machine.
Je vais ensuite ajouter un fichier /etc/falco/rules.d/patch-rules.yaml avec le contenu suivant :
- rule: search for sensitives files
condition: and user.name != "mngmt"
override:
condition: append
Astuce
Il est aussi possible de faire des override sur des listes et des macros :
- list: searching_binaries
items: ['grep', 'fgrep', 'egrep', 'rgrep', 'locate', 'find']
- list: searching_binaries
items: ['rg', 'hgrep', 'ugrep']
override:
items: append
Nous venons d’utiliser un override permettant d’ajouter une condition à notre règle. Mais override permet également de remplacer une condition entière d’une règle. Par exemple :
- rule: search for sensitives files
condition: >
spawned_process and proc.name in (searching_binaries) and
(
proc.args contains "id_rsa" or
proc.args contains "id_ed25519" or
proc.args contains "kube/config"
) and user.name != "mngmt"
override:
condition: replace
L’inconvénient de cette méthode est que cela peut devenir compliqué à gérer si on a beaucoup de règles et d’overrides dans plusieurs fichiers. On s’y perd facilement.
Plutôt que de rajouter un override pour modifier une condition afin d’exclure un contexte, il est possible de passer par les exceptions.
- rule: search for sensitives files
desc: Detect if someone is searching for a sensitive file
condition: >
spawned_process and proc.name in (searching_binaries) and
(
proc.args contains "id_rsa" or
proc.args contains "id_ed25519" or
proc.args contains "kube/config"
)
exceptions:
- name: ssh_script
fields: user.name
values: [mngmt]
output: Someone is searching for a sensitive file (file=%proc.args pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%p
roc.pname command=%proc.cmdline terminal=%proc.tty container_id=%container.id container_image=%container.image.repository container_image_tag=%container.image.tag container_name=%container.name)
priority: INFO
tags: [sensitive_data, ssh]
Cette écriture est plus propre et me permet d’ajouter de nombreuses exceptions sans avoir à modifier la règle principale.
Je peux par ailleurs affiner mon exception en ajoutant d’autres champs pour être plus précis.
- rule: search for sensitives files
desc: Detect if someone is searching for a sensitive file
condition: >
spawned_process and proc.name in (searching_binaries) and
(
proc.args contains "id_rsa" or
proc.args contains "id_ed25519" or
proc.args contains "kube/config"
)
exceptions:
- name: context_1
fields: [user.name, proc.cwd, user.shell]
values:
- [mngmt, /home/mngmt/, /bin/sh]
output: Someone is currently searching for a sensitive file (%proc.cwd file=%proc.args pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%pr
oc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty container_id=%container.id container_image=%container.image.repository container_image_tag=%container.image.tag container_name=%container.name)
priority: INFO
tags: [sensitive_data, ssh]
L’usage des exceptions permet d’éviter d’avoir un champ “condition” trop long et trop difficile à maintenir.
Pour l’exemple, j’ai utilisé un cas assez simple mais c’est extrêmement dangereux de laisser un utilisateur chercher des fichiers sensibles. Je vous invite plutôt à reconsidérer la manière dont vous gérez les accès à ces fichiers plutôt que de créer une exception dans Falco.
Falco et les conteneurs
Falco s’intègre très bien avec les conteneurs et est capable de détecter les événements qui se produisent à l’intérieur de ceux-ci.
On peut ainsi surveiller les conteneurs démarrés en utilisant les valeurs de la classe container (par exemple, container.id, container.name, container.image).
- macro: container_started
condition: ((evt.type = container) or (spawned_process and proc.vpid=1))
- rule: New container with tag latest
desc: Detect if a new container with the tag "latest" is started
condition: >
container_started and container.image.tag="latest"
output: A new container with the tag "latest" is started (container_id=%container.id container_image=%container.image.repository container_image_tag=%container.image.tag container_name=%container.name k8s_ns=%k8s.ns.name k8s_pod_name=%k8s.pod.name)
priority: INFO
tags: [container, invalid_tag]
Les règles existantes sont déjà adaptées pour fonctionner dans des conteneurs (comme les règles de détection de shell, de recherche de fichiers sensibles, etc.). Mais il faut bien ajouter les champs container.id, container.image, container.name dans l’output pour avoir des informations sur le conteneur concerné lorsqu’une alerte est déclenchée.
Petite précision : Sans l’usage de container_started, la règle ne surveillerait aucun appel système et Falco serait obligé de surveiller chaque appel système pour vérifier s’il s’agit d’un conteneur avec le tag latest, ce qui pose de gros problèmes de performance comme précisé dans le chapitre Les règles Falco.
Par exemple, réutilisons la règle search for sensitives files pour ajouter les champs container.id, container.image et container.name dans l’output.
- rule: search for sensitives files
desc: Detect if someone is searching for a sensitive file
condition: >
spawned_process and proc.name in (searching_binaries) and
(
proc.args contains "id_rsa" or
proc.args contains "id_ed25519" or
proc.args contains "kube/config"
)
output: Someone is searching for a sensitive file (file=%proc.args pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty container_id=%container.id container_image=%container.image.repository container_image_tag=%container.image.tag container_name=%container.name)
priority: INFO
tags: [sensitive_data, ssh]
Lorsqu’une alerte est déclenchée, on obtient des informations sur le conteneur concerné (comme l’ID, le nom, l’image, etc.).
{
"hostname": "falco-linux",
"output": "22:50:25.195959798: Informational Someone is searching for a sensitive file (file=-r id_rsa pcmdline=ash gparent=containerd-shim evt_type=execve user=root user_uid=0 user_loginuid=-1 process=grep proc_exepath=/bin/busybox parent=ash command=grep -r id_rsa terminal=34816 container_id=b578c3492ecf container_image=alpine container_image_tag=latest container_name=sharp_lovelace)",
"priority": "Informational",
"rule": "search for sensitives files",
"source": "syscall",
"tags": [
"sensitive_data",
"ssh"
],
"time": "2024-04-06T20:50:25.195959798Z",
"output_fields": {
"container.id": "b578c3492ecf",
"container.image.repository": "alpine",
"container.image.tag": "latest",
"container.name": "sharp_lovelace",
"evt.time": 1712436625195959800,
"evt.type": "execve",
"proc.aname[2]": "containerd-shim",
"proc.args": "-r id_rsa",
"proc.cmdline": "grep -r id_rsa",
"proc.exepath": "/bin/busybox",
"proc.name": "grep",
"proc.pcmdline": "ash",
"proc.pname": "ash",
"proc.tty": 34816,
"user.loginuid": -1,
"user.name": "root",
"user.uid": 0
}
}
Pour définir si une règle doit s’appliquer ou non aux conteneurs, il est possible de rajouter les conditions suivantes :
- La condition
container.id=hostpour celles qui ne doivent pas s’y appliquer. - La condition
container.id!=hostpour celles qui doivent s’appliquer uniquement aux conteneurs.
Sans ces conditions, les règles s’appliqueront à tous les processus, y compris ceux qui ne sont pas dans des conteneurs.
Faille xz (CVE-2024-3094)
Parlons actualité ! Une faille a été découverte dans la librairie liblzma qui permet à un attaquant précis de contourner l’authentification SSHD à l’aide d’une clé ssh privée. Cette faille est référencée sous le nom de CVE-2024-3094 et est critique.
Sysdig a publié une règle pour détecter si la librairie liblzma faillible est chargée par SSHD. La voici :
- rule: Backdoored library loaded into SSHD (CVE-2024-3094)
desc: A version of the liblzma library was seen loading which was backdoored by a malicious user in order to bypass SSHD authentication.
condition: open_read and proc.name=sshd and (fd.name endswith "liblzma.so.5.6.0" or fd.name endswith "liblzma.so.5.6.1")
output: SSHD Loaded a vulnerable library (| file=%fd.name | proc.pname=%proc.pname gparent=%proc.aname[2] ggparent=%proc.aname[3] gggparent=%proc.aname[4] image=%container.image.repository | proc.cmdline=%proc.cmdline | container.name=%container.name | proc.cwd=%proc.cwd proc.pcmdline=%proc.pcmdline user.name=%user.name user.loginuid=%user.loginuid user.uid=%user.uid user.loginname=%user.loginname image=%container.image.repository | container.id=%container.id | container_name=%container.name| proc.cwd=%proc.cwd )
priority: WARNING
tags: [host,container]
Si j’ajoute cette fameuse librairie liblzma (version 5.6.0) dans le dossier /lib/x86_64-linux-gnu/ et que je démarre le service sshd à partir de celle-ci, Falco devrait détecter l’alerte…
{
"hostname": "falco-linux",
"output": "23:11:24.780959791: Warning SSHD Loaded a vulnerable library (| file=/lib/x86_64-linux-gnu/liblzma.so.5.6.0 | proc.pname=systemd gparent=<NA> ggparent=<NA> gggparent=<NA> image=<NA> | proc.cmdline=sshd -D | container.name=host | proc.cwd=/ proc.pcmdline=systemd install user.name=root user.loginuid=-1 user.uid=0 user.loginname=<NA> image=<NA> | container.id=host | container_name=host| proc.cwd=/ )",
"priority": "Warning",
"rule": "Backdoored library loaded into SSHD (CVE-2024-3094)",
"source": "syscall",
"tags": [
"container",
"host"
],
"time": "2024-04-06T21:11:24.780959791Z",
"output_fields": {
"container.id": "host",
"container.image.repository": null,
"container.name": "host",
"evt.time": 1712437884780959700,
"fd.name": "/lib/x86_64-linux-gnu/liblzma.so.5.6.0",
"proc.aname[2]": null,
"proc.aname[3]": null,
"proc.aname[4]": null,
"proc.cmdline": "sshd -D",
"proc.cwd": "/",
"proc.pcmdline": "systemd install",
"proc.pname": "systemd",
"user.loginname": "<NA>",
"user.loginuid": -1,
"user.name": "root",
"user.uid": 0
}
}
Bingo ! Falco a bien détecté l’alerte et nous pouvons réagir en conséquence pour corriger cette faille.
Le driver-loader sur Falco
Lorsque j’ai installé Falco pour la première fois, j’ai pu voir qu’il avait besoin de charger un ‘driver’. Celui-ci est indispensable pour Falco si vous utilisez le mode kmod (module kernel) ou simple ebpf. Le mode modern_ebpf est quant à lui exempté de driver.
Si néanmoins vous utilisez un mode nécessitant un driver, vous verrez dans les logs du pod (dans un contexte Kubernetes) que le driver est téléchargé et installé dans un emptyDir pour être monté dans le pod Falco.
$ kubectl logs -l app.kubernetes.io/name=falco -n falco -c falco-driver-loader
2024-04-17 21:49:01 INFO Removing eBPF probe symlink
└ path: /root/.falco/falco-bpf.o
2024-04-17 21:49:01 INFO Trying to download a driver.
└ url: https://download.falco.org/driver/7.0.0%2Bdriver/x86_64/falco_debian_6.1.76-1-cloud-amd64_1.o
2024-04-17 21:49:01 INFO Driver downloaded.
└ path: /root/.falco/7.0.0+driver/x86_64/falco_debian_6.1.76-1-cloud-amd64_1.o
2024-04-17 21:49:01 INFO Symlinking eBPF probe
├ src: /root/.falco/7.0.0+driver/x86_64/falco_debian_6.1.76-1-cloud-amd64_1.o
└ dest: /root/.falco/falco-bpf.o
2024-04-17 21:49:01 INFO eBPF probe symlinked
Hors Kubernetes, si nous démarrons Falco sans driver, nous aurons une erreur :
$ falco -o engine.kind=ebpf
Fri Apr 19 08:20:07 2024: Falco version: 0.37.1 (x86_64)
Fri Apr 19 08:20:07 2024: Loading rules from file /etc/falco/falco_rules.yaml
Fri Apr 19 08:20:07 2024: Loading rules from file /etc/falco/falco_rules.local.yaml
Fri Apr 19 08:20:07 2024: Loaded event sources: syscall
Fri Apr 19 08:20:07 2024: Enabled event sources: syscall
Fri Apr 19 08:20:07 2024: Opening 'syscall' source with BPF probe. BPF probe path: /root/.falco/falco-bpf.o
Fri Apr 19 08:20:07 2024: An error occurred in an event source, forcing termination...
Events detected: 0
Rule counts by severity:
Triggered rules by rule name:
Error: can't open BPF probe '/root/.falco/falco-bpf.o'
Sur Kubernetes, un initContainer démarre automatiquement pour télécharger le driver. Hors cluster, il faut télécharger ce driver via la commande falcoctl driver install --type ebpf.
Cette configuration ne me plait pas trop. Que se passerait-il si le driver était corrompu par un pirate ? Ou si le serveur de téléchargement était indisponible alors que j’ajoute de nouvelles machines à mon infra ? L’idéal est d’avoir un fonctionnement totalement airgap (sans connexion externe au cluster) pour Falco.
Il est possible de créer une image Docker de Falco avec le driver déjà intégré, mais cela peut poser des problèmes de maintenance (il faudra mettre à jour l’image à chaque nouvelle version de Falco, et celle-ci ne sera pas compatible avec toutes les versions de noyau).
Une solution proposée par Sysdig est d’avoir son propre serveur Web pour héberger les drivers Falco et de les télécharger depuis ce même serveur (celui-ci peut même être un pod accompagné par un service Kubernetes).
Pour préciser une URL de téléchargement différente, il faut paramétrer la variable d’environnement FALCOCTL_DRIVER_REPOS au pod falco-driver-loader.
Dans le chart Helm, cela se fait à la clé driver.loader.initContainer.env :
driver:
kind: ebpf
loader:
initContainer:
env:
- name: FALCOCTL_DRIVER_REPOS
value: "http://driver-httpd/"
Falco sur Kubernetes
Je n’allais quand même pas vous laisser sans vous montrer comment installer Falco sur un cluster Kubernetes ! 😄
En plus d’être compatible avec les conteneurs, les règles Falco sont déjà prêtes à l’emploi pour Kubernetes. Depuis un cluster, nous avons accès à de nouvelles variables pour créer nos règles (ou les utiliser dans les outputs) :
k8s.ns.name- Nom du namespace Kubernetes.k8s.pod.name- Nom du pod Kubernetes.k8s.pod.label/k8s.pod.labels- Labels du pod Kubernetes.k8s.pod.cni.json- Informations CNI du pod Kubernetes.
À savoir que puisque Falco surveille les appels systèmes, les règles Falco installées par le chart Helm sont également valides sur les hôtes (hors des pods).
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm install falco falcosecurity/falco -n falco -f values.yaml --create-namespace
tty: true
falcosidekick:
enabled: true
webui:
enabled: true
# Vous pouvez ajouter des configurations supplémentaires pour Falco-Sidekick pour router les notifications comme ci-dessous
# slack:
# webhookurl: https://hooks.slack.com/services/XXXXX/XXXXX/XXXXX
# channel: "#falco-alerts"
driver:
kind: modern_ebpf
Lorsqu’on veut ajouter une règle, la méthode ‘simple’ est de le faire dans le values.yaml du chart Helm et de mettre à jour le déploiement via helm upgrade --reuse-values -n falco falco falcosecurity/falco -f falco-rules.yaml. Dès lors que le champ customRules est présent, le chart Helm va créer une ConfigMap avec les règles personnalisées, vous pouvez aussi vous en servir pour modifier les règles.
customRules:
restrict_tag.yaml: |
- macro: container_started
condition: >
((evt.type = container or
(spawned_process and proc.vpid=1)))
- list: namespace_system
items: [kube-system, cilium-system]
- macro: namespace_allowed_to_use_latest_tag
condition: not (k8s.ns.name in (namespace_system))
- rule: Container with latest tag outside kube-system and cilium-system
desc: Detects containers with the "latest" tag started in namespaces other than kube-system and cilium-system
condition: >
container_started
and container.image endswith "latest"
and namespace_allowed_to_use_latest_tag
output: "Container with 'latest' tag detected outside kube-system and cilium-system (user=%user.name container_id=%container.id image=%container.image)"
priority: WARNING
tags: [k8s, container, latest_tag]
Note: J’ai écrit la règle réagissant à un conteneur avec le tag latest pour montrer qu’il était possible de réagir aux métadonnées des pods, mais il serait plus judicieux de confier cette fonction à un Kyverno ou à une Admission Policy
Pour ceux qui ne s’en contentent pas, nous verrons plus bas comment automatiser l’ajout des règles depuis des artéfacts externes (et sans mettre à jour notre déploiement Helm pour ajouter de nouvelles règles).
Astuce
Rien ne vous oblige à n’avoir qu’un seul fichier values.yaml contenant la configuration ET les règles Falco. Vous pouvez très bien séparer les deux pour plus de clarté.
helm install falco falcosecurity/falco -n falco -f values.yml -f falco-rules.yaml --create-namespace
Maintenant, si je démarre un conteneur avec l’image nginx:latest dans le namespace default :
kubectl run nginx --image=nginx:latest -n default
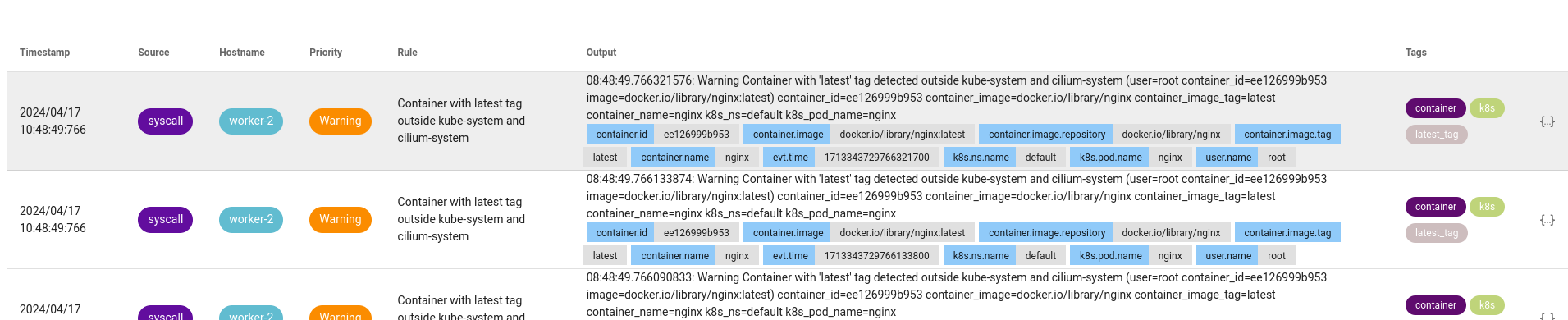
Falco a bien détecté l’alerte et m’a notifié que le conteneur nginx avec l’image nginx:latest a été démarré dans le namespace default.
Détection, alerte et réponse
Pour l’instant, la grande différence entre Falco et son concurrent sur Kubernetes : c’est le fait de pouvoir réagir à une alerte levée par un pod. Falco ne peut que détecter et alerter, mais ne peut pas réagir (comme par exemple, tuer le pod ou le mettre en quarantaine).
Pour cela, il existe un outil nommé Falco Talon, développé par un mainteneur de Falco.
C’est un outil réagissant aux alertes fonctionnant de la même manière que Falco-Sidekick (il est même possible de les utiliser ensemble). À la réception d’une alerte, Falco Talon va agir dans l’objectif de bloquer l’attaque.
⚠️ Attention, le programme est encore en cours de développement, il est possible que vous ayiez des différences avec ce que je vais vous montrer. ⚠️
Voici les actions possibles avec Falco Talon :
- Tuer le pod (
kubernetes:terminate) - Ajouter / Supprimer un label (
kubernetes:labelize) - Créer une NetworkPolicy (
kubernetes:networkpolicy) - Lancer une commande / script dans le pod (
kubernetes:execetkubernetes:script) - Supprimer une ressource (
kubernetes:delete) (autre que le pod) - Bloquer le trafic en sortie (
calico:networkpolicy) (nécessite Calico)
Chaque action est paramétrable et rien ne vous empêche d’avoir plusieurs fois la même action avec des paramètres différents.
Pour l’installer, un chart Helm est disponible sur le dépôt Github (un index sera bien sûr disponible plus tard) :
git clone https://github.com/Falco-Talon/falco-talon.git
cd falco-talon/deployment/helm/
helm install falco-talon . -n falco --create-namespace
Une fois Talon installé, il nous faut configurer Falco-Sidekick pour qu’il envoie les alertes à Talon. Pour se faire, nous devons modifier notre values.yaml pour y ajouter la configuration suivante :
falcosidekick:
enabled: true
config:
webhook:
address: "http://falco-talon:2803"
Et voilà ! Falco-Sidekick enverra les alertes à Falco Talon qui pourra réagir en conséquence. À nous de le configurer pour qu’il réagisse comme nous le souhaitons à nos alertes.
Les fichiers à modifier sont directement présents dans le dépôt Github (dans le chart Helm) à l’emplacement ./deployment/helm/rules.yaml et ./deployment/helm/rules_overrides.yaml.
Voici un extrait de la configuration par défaut de Talon (dans le fichier rules.yaml) :
- action: Labelize Pod as Suspicious
actionner: kubernetes:labelize
parameters:
labels:
suspicious: true
- rule: Terminal shell in container
match:
rules:
- Terminal shell in container
output_fields:
- k8s.ns.name!=kube-system, k8s.ns.name!=falco
actions:
- action: Labelize Pod as Suspicious
Cela crée l’action Labelize Pod as Suspicious qui va ajouter un label suspicious: true au pod lorsqu’un terminal est détecté dans un conteneur. Cette action ne va s’appliquer que si l’alerte Terminal shell in container est déclenchée et que cette alerte possède le champ k8s.ns.name différent de kube-system et falco.
Simple, non ? 😄
Pour tester ça, démarrons un pod nginx :
$ kubectl run nginx --image=nginx:latest -n default
pod/nginx created
$ kubectl get pods nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 10s run=nginx
Aucun label suspicious n’est présent. Mais si je démarre un terminal dans le pod nginx…
$ kubectl exec pod/nginx -it -- bash
root@nginx:/# id
uid=0(root) gid=0(root) groups=0(root)
root@nginx:/#
exit
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 16m run=nginx,suspicious=true
Un label suspicious a été ajouté au pod nginx ! 😄
Nous pouvons également supprimer un label pour qu’un service ne pointe plus vers ce pod.
Un autre souci est que tant que le pod est en cours d’exécution, l’attaquant peut continuer son attaque, télécharger des payloads, accéder aux autres services, etc. Une solution serait alors d’ajouter une NetworkPolicy pour bloquer le trafic sortant du pod.
Voici mon nouveau fichier de règles :
- action: Disable outbound connections
actionner: kubernetes:networkpolicy
parameters:
allow:
- 127.0.0.1/32
- action: Labelize Pod as Suspicious
actionner: kubernetes:labelize
parameters:
labels:
app: ""
suspicious: true
- rule: Terminal shell in container
match:
rules:
- Terminal shell in container
output_fields:
- k8s.ns.name!=kube-system, k8s.ns.name!=falco
actions:
- action: Disable outbound connections
- action: Labelize Pod as Suspicious
D’après vous, que va-t-il se passer si je lance un terminal dans un pod ?
On va voir ça de suite un Deployment créant un pod netshoot (image utilisée pour des tests réseau).
apiVersion: apps/v1
kind: Deployment
metadata:
name: netshoot
spec:
replicas: 1
selector:
matchLabels:
app: netshoot
template:
metadata:
labels:
app: netshoot
spec:
containers:
- name: netshoot
image: nicolaka/netshoot
command: ["/bin/bash"]
args: ["-c", "while true; do sleep 60;done"]
Nativement (sans aucune NetworkPolicy), le pod netshoot peut accéder à internet, ou à d’autres services du cluster. Mais une fois que j’ai appliqué ma règle et démarré un terminal dans le pod netshoot, le trafic sortant est bloqué, le label suspicious est ajouté au pod le label app est supprimé.
Comme nous supprimons le label app=netshoot, le Deployment va recréer un nouveau pod pour respecter le nombre de replicas.
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
netshoot-789557564b-8gc7m 1/1 Running 0 13m app=netshoot,pod-template-hash=789557564b
$ kubectl exec deploy/netshoot -it -- bash
netshoot-789557564b-8gc7m:~# ping -c1 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
netshoot-789557564b-8gc7m:~# curl http://kubernetes.default.svc.cluster.local:443 # Aucune réponse
netshoot-789557564b-8gc7m:~# exit
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
netshoot-789557564b-8gc7m 1/1 Running 0 14m pod-template-hash=789557564b,suspicious=true
netshoot-789557564b-grg8k 1/1 Running 0 54s app=netshoot,pod-template-hash=789557564b
Ainsi, on peut facilement isoler des pods en quarantaine et bloquer tout trafic sortant sans que le Deployment ne soit impacté.
La networkpolicy créée par Talon va utiliser le label suspicious=true comme sélecteur. En revanche, une fois que nous avons supprimé le pod, la NetworkPolicy est toujours présente. Il faudra donc la supprimer manuellement.
En plus d’être notifié par Falco-Sidekick lors d’une alerte, Talon peut également nous envoyer un petit message pour nous prévenir de l’action effectuée.
Par défaut, Talon va générer des events dans le namespace de l’alerte. Pour les voir, il suffit de lancer la commande : kubectl get events --sort-by=.metadata.creationTimestamp.
24m Normal falco-talon:kubernetes:networkpolicy:success pod Status: success...
24m Normal falco-talon:kubernetes:labelize:success pod Status: success...
Mais il est possible de configurer Talon pour qu’il envoie des messages sur un webhook, un channel Slack, un SMTP, Une requête dans Loki, etc.
Dans mon cas, je vais le configurer pour qu’il m’envoie un message sur un webhook, je vais mettre à jour mon values.yaml de Falco Talon avec les valeurs suivantes :
defaultNotifiers:
- webhook
- k8sevents
notifiers:
webhook:
url: "https://webhook.site/045451d8-ab16-45d9-a65e-7d1858f8c5b7"
http_method: "POST"
Je mets à jour mon chart Helm avec la commande helm upgrade --reuse-values -n falco falco-talon . -f values.yaml. Et dès que Talon aura effectué une action, je recevrai un message sur mon webhook.
Par exemple, pour reprendre le cas où Talon déploie une NetworkPolicy pour bloquer le trafic sortant d’un pod, je vais recevoir un message comme celui-ci :
{
"objects": {
"Namespace": "default",
"Networkpolicy": "netshoot-789557564b-lwgfs",
"Pod": "netshoot-789557564b-lwgfs"
},
"trace_id": "51ac05de-f97c-45c9-9ac7-cb6f93062f8a",
"rule": "Terminal shell in container",
"event": "A shell was spawned in a container with an attached terminal (evt_type=execve user=root user_uid=0 user_loginuid=-1 process=bash proc_exepath=/bin/bash parent=containerd-shim command=bash terminal=34816 exe_flags=EXE_WRITABLE container_id=0a1197d327ff container_image=docker.io/nicolaka/netshoot container_image_tag=latest container_name=netshoot k8s_ns=default k8s_pod_name=netshoot-789557564b-lwgfs)",
"message": "action",
"output": "the networkpolicy 'netshoot-789557564b-lwgfs' in the namespace 'default' has been updated",
"actionner": "kubernetes:networkpolicy",
"action": "Disable outbound connections",
"status": "success"
}
GitOps et Falco
Depuis mon article sur ArgoCD dans lequel je vous parlais du GitOps et du X-as-Code, vous vous doutez peut-être que je vais vous parler de la gestion des règles Falco ‘as code’. Et vous avez raison !
Voyons comment gérer notre configuration Falco en mode “Pull” depuis Falco.
Si je possède une infra de ~100 machines, je ne vais pas m’amuser à me connecter à chacune d’elles pour modifier ou mettre à jour les règles Falco machine par machine.
C’est pourquoi Falco possède un outil nommé falcoctl qui permet de récupérer la configuration Falco (plugins, règles, etc.) depuis un serveur externe (c’est d’ailleurs depuis ce même outil que l’on peut télécharger les drivers). Pour cela, Falco utilise les OCI Artifacts pour installer les règles et les plugins.
$ falcoctl artifact list
INDEX ARTIFACT TYPE REGISTRY REPOSITORY
falcosecurity application-rules rulesfile ghcr.io falcosecurity/rules/application-rules
falcosecurity cloudtrail plugin ghcr.io falcosecurity/plugins/plugin/cloudtrail
falcosecurity cloudtrail-rules rulesfile ghcr.io falcosecurity/plugins/ruleset/cloudtrail
falcosecurity dummy plugin ghcr.io falcosecurity/plugins/plugin/dummy
falcosecurity dummy_c plugin ghcr.io falcosecurity/plugins/plugin/dummy_c
falcosecurity falco-incubating-rules rulesfile ghcr.io falcosecurity/rules/falco-incubating-rules
falcosecurity falco-rules rulesfile ghcr.io falcosecurity/rules/falco-rules
falcosecurity falco-sandbox-rules rulesfile ghcr.io falcosecurity/rules/falco-sandbox-rules
# ...
Lorsqu’on installe Falco, le paquet contient déjà des règles par défaut (celles dans l’artéfact falco-rules), il est alors possible de rajouter un ensemble de règles de cette manière :
$ falcoctl artifact install falco-incubating-rules
2024-04-17 18:36:11 INFO Resolving dependencies ...
2024-04-17 18:36:12 INFO Installing artifacts refs: [ghcr.io/falcosecurity/rules/falco-incubating-rules:latest]
2024-04-17 18:36:12 INFO Preparing to pull artifact ref: ghcr.io/falcosecurity/rules/falco-incubating-rules:latest
2024-04-17 18:36:12 INFO Pulling layer d306556e1c90
2024-04-17 18:36:13 INFO Pulling layer 93a62ab52683
2024-04-17 18:36:13 INFO Pulling layer 5e734f96181c
2024-04-17 18:36:13 INFO Verifying signature for artifact
└ digest: ghcr.io/falcosecurity/rules/falco-incubating-rules@sha256:5e734f96181cda9fc34e4cc6a1808030c319610e926ab165857a7829d297c321
2024-04-17 18:36:13 INFO Signature successfully verified!
2024-04-17 18:36:13 INFO Extracting and installing artifact type: rulesfile file: falco-incubating_rules.yaml.tar.gz
2024-04-17 18:36:13 INFO Artifact successfully installed
├ name: ghcr.io/falcosecurity/rules/falco-incubating-rules:latest
├ type: rulesfile
├ digest: sha256:5e734f96181cda9fc34e4cc6a1808030c319610e926ab165857a7829d297c321
└ directory: /etc/falco
Dès que la commande est exécutée, falcoctl va télécharger les règles depuis l’image OCI ghcr.io/falcosecurity/rules/falco-incubating-rules:latest et les installer dans le dossier /etc/falco (en l’occurrence, ici c’est le fichier /etc/falco/falco-incubating_rules.yaml qui est créé).
En revanche, pour une infrastructure durable, je ne vais pas m’amuser à taper les commandes bash à chaque fois que je veux installer de nouvelles règles. Nous allons donc jeter un coup d’œil au fichier de configuration de falcoctl (qui a dû être généré lors de votre première exécution de falcoctl), celui-ci se trouve à l’emplacement /etc/falcoctl/config.yaml.
artifact:
follow:
every: 6h0m0s
falcoversions: http://localhost:8765/versions
refs:
- falco-rules:0
driver:
type: modern_ebpf
name: falco
repos:
- https://download.falco.org/driver
version: 7.0.0+driver
hostroot: /
indexes:
- name: falcosecurity
url: https://falcosecurity.github.io/falcoctl/index.yaml
Nous allons tout d’abord nous intéresser à la partie follow de la configuration. Celle-ci permet de suivre les mises à jour des règles Falco et de les installer automatiquement.
Pour reprendre l’exemple précédent, plutôt que d’installer de manière ponctuelle les règles falco-incubating-rules, nous allons les ajouter dans la configuration falcoctl pour qu’elles soient installées automatiquement via la commande falcoctl artifact follow
Pour cela, nous allons ajouter les règles falco-incubating-rules dans la configuration falcoctl :
artifact:
follow:
every: 6h0m0s
falcoversions: http://localhost:8765/versions
refs:
- falco-incubating-rules
# ...
Ensuite, la commande falcoctl artifact follow va installer les règles falco-incubating-rules et les mettre à jour automatiquement toutes les six heures si une nouvelle version est disponible sur le tag latest (en comparant le digest de l’artéfact).
falcoctl artifact follow
2024-04-17 18:50:06 INFO Creating follower artifact: falco-incubating-rules:latest check every: 6h0m0s
2024-04-17 18:50:06 INFO Starting follower artifact: ghcr.io/falcosecurity/rules/falco-incubating-rules:latest
2024-04-17 18:50:06 INFO Found new artifact version followerName: ghcr.io/falcosecurity/rules/falco-incubating-rules:latest tag: latest
2024-04-17 18:50:10 INFO Artifact correctly installed
├ followerName: ghcr.io/falcosecurity/rules/falco-incubating-rules:latest
├ artifactName: ghcr.io/falcosecurity/rules/falco-incubating-rules:latest
├ type: rulesfile
├ digest: sha256:d4c03e000273a0168ee3d9b3dfb2174e667b93c9bfedf399b298ed70f37d623b
└ directory: /etc/falco
Information
Petit rappel : falco va automatiquement reloader les règles lorsqu’un fichier configuré dans le /etc/falco/falco.yaml est modifié.
À savoir que par défaut, falcoctl va utiliser le tag latest pour les images OCI, mais je vous recommande fortement de spécifier une version précise (ex: 1.0.0). Pour connaître les versions disponibles d’un artéfact, nous avons la commande falcoctl artifact info. Par exemple :
$ falcoctl artifact info falco-incubating-rules
REF TAGS
ghcr.io/falcosecurity/rules/falco-incubating-rules 2.0.0-rc1, sha256-8b8dd8ee8eec6b0ba23b6a7bc3926a48aaa8e56dc42837a0ad067988fdb19e16.sig, 2.0.0, 2.0, 2, latest, sha256-1391a1df4aa230239cff3efc7e0754dbf6ebfa905bef5acadf8cdfc154fc1557.sig, 3.0.0-rc1, sha256-de9eb3f8525675dc0ffd679955635aa1a8f19f4dea6c9a5d98ceeafb7a665170.sig, 3.0.0, 3.0, 3, sha256-555347ba5f7043f0ca21a5a752581fb45050a706cd0fb45aabef82375591bc87.sig, 3.0.1, sha256-5e734f96181cda9fc34e4cc6a1808030c319610e926ab165857a7829d297c321.sig
Créer ses propres artéfacts
Nous avons vu comment utiliser les artéfacts de falcoctl proposés par le registre falcosecurity, maintenant, à nous de créer nos propres artéfacts !
Je vais commencer par créer un fichier never-chmod-777.yaml contenant une règle Falco :
- macro: chmod_777
condition: (evt.arg.mode contains S_IXOTH and evt.arg.mode contains S_IWOTH and evt.arg.mode contains S_IROTH and evt.arg.mode contains S_IXGRP and evt.arg.mode contains S_IWGRP and evt.arg.mode contains S_IRGRP and evt.arg.mode contains S_IXUSR and evt.arg.mode contains S_IWUSR and evt.arg.mode contains S_IRUSR)
- rule: chmod 777
desc: Detect if someone is trying to chmod 777 a file
condition: >
evt.type=fchmodat and chmod_777
output: Someone is trying to chmod 777 a file (file=%fd.name pcmdline=%proc.pcmdline gparent=%proc.aname[2] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty)
priority: ERROR
tags: [chmod, security]
Pour packager ce fichier dans un artéfact OCI, nous allons commencer par nous authentifier sur une registry Docker (ici, Github Container Registry) :
docker login ghcr.io
Pour créer notre image, pas de docker build, nous pouvons le faire à partir de falcoctl :
$ falcoctl registry push --type rulesfile \
--version 1.0.0 \
ghcr.io/cuistops/never-chmod-777:1.0.0 \
never-chmod-777.yaml
2024-04-17 19:03:10 INFO Preparing to push artifact name: ghcr.io/cuistops/never-chmod-777:1.0.0 type: rulesfile
2024-04-17 19:03:10 INFO Pushing layer ac9ec4319805
2024-04-17 19:03:11 INFO Pushing layer a449a3b9a393
2024-04-17 19:03:12 INFO Pushing layer 9fa17441da69
2024-04-17 19:03:12 INFO Artifact pushed
├ name: ghcr.io/cuistops/never-chmod-777:1.0.0
├ type:
└ digest: sha256:9fa17441da69ec590f3d9c0a58c957646d55060ffa2deae84d99b513a5041e6d
Voilà ! Nous avons notre image OCI ghcr.io/cuistops/never-chmod-777:1.0.0 contenant notre règle Falco. Il ne reste qu’à l’ajouter dans la configuration falcoctl :
artifact:
follow:
every: 6h0m0s
falcoversions: http://localhost:8765/versions
refs:
- falco-rules:3
- ghcr.io/cuistops/never-chmod-777:1.0.0
Automatiquement, falcoctl artifact follow va créer le fichier /etc/falco/never-chmod-777.yaml avec ma règle.
$ falcoctl artifact follow
2024-04-17 19:07:29 INFO Creating follower artifact: falco-rules:3 check every: 6h0m0s
2024-04-17 19:07:29 INFO Creating follower artifact: ghcr.io/cuistops/never-chmod-777:1.0.0 check every: 6h0m0s
2024-04-17 19:07:29 INFO Starting follower artifact: ghcr.io/falcosecurity/rules/falco-rules:3
2024-04-17 19:07:29 INFO Starting follower artifact: ghcr.io/cuistops/never-chmod-777:1.0.0
2024-04-17 19:07:30 INFO Found new artifact version followerName: ghcr.io/falcosecurity/rules/falco-rules:3 tag: latest
2024-04-17 19:07:30 INFO Found new artifact version followerName: ghcr.io/cuistops/never-chmod-777:1.0.0 tag: 1.0.0
2024-04-17 19:07:33 INFO Artifact correctly installed
├ followerName: ghcr.io/cuistops/never-chmod-777:1.0.0
├ artifactName: ghcr.io/cuistops/never-chmod-777:1.0.0
├ type: rulesfile
├ digest: sha256:9fa17441da69ec590f3d9c0a58c957646d55060ffa2deae84d99b513a5041e6d
└ directory: /etc/falco
2024-04-17 19:07:33 INFO Artifact correctly installed
├ followerName: ghcr.io/falcosecurity/rules/falco-rules:3
├ artifactName: ghcr.io/falcosecurity/rules/falco-rules:3
├ type: rulesfile
├ digest: sha256:d4c03e000273a0168ee3d9b3dfb2174e667b93c9bfedf399b298ed70f37d623b
└ directory: /etc/falco
Dans un cluster Kubernetes, il faut préciser les artéfacts à suivre dans le values.yaml du chart Helm à l’emplacement falcoctl.config.artifacts.follow.refs :
falcoctl:
config:
artifacts:
follow:
refs:
- falco-rules:3
- ghcr.io/cuistops/never-chmod-777:1.0.0
À noter que lors de la création d’un artifact avec falcoctl, il va copier le chemin en argument de la commande falcoctl registry push et déposer le fichier au même chemin en prenant /etc/falco en racine. Cela veut donc dire que si je lui donne le chemin ./rulartéfacter-chmod-777.yaml en générant mon artifact, le fichier sera déposé dans /etc/falco/rules.d/never-chmod-777.yaml. Il faut donc prévoir que le chemin soit correctement créé et/ou que falco soit bien configuré pour lire les règles à cet endroit.
Pour rappel, Falco va automatiquement recharger sa configuration aux emplacements :
/etc/falco/falco_rules.yaml/etc/falco/rules.d/*/etc/falco/falco_rules.local.yaml
Si je dépose un fichier de règle à l’emplacement /etc/falco/never-chmod-777.yaml, Falco ne va (par défaut) pas le lire. Une solution viable est de déposer les règles dans le dossier /etc/falco/rules.d (présent dans la configuration de Falco), mais celui-ci n’est pas créé par défaut.
Sur Kubernetes, j’ai rajouté un initContainer pour créer le répertoire rules.d dans le volume rulesfiles-install-dir et je demande à falcoctl de déposer les règles dans ce répertoire (sachant que le volume rulesfiles-install-dir est monté dans /etc/falco).
extra:
initContainers:
- name: create-rulesd-dir
image: busybox
command: ["mkdir", "-p", "/etc/falco/rules.d"]
volumeMounts:
- name: rulesfiles-install-dir
mountPath: /etc/falco
falcoctl:
artifact:
install:
args: ["--log-format=json", "--rulesfiles-dir", "/rulesfiles/rules.d/"]
follow:
args: ["--log-format=json", "--rulesfiles-dir", "/rulesfiles/rules.d/"]
config:
artifact:
follow:
refs:
- falco-rules:3
- ghcr.io/cuistops/never-chmod-777:1.0.0
Avec ce fonctionnement, mes artéfacts sont directement installés dans un dossier surveillé par Falco et je n’ai pas besoin de modifier sa configuration pour lui spécifier les nouveaux fichiers de règles.
Github Action pour générer les artéfacts
Pour automatiser la génération des artéfacts, nous pouvons utiliser Github Actions (ou Gitlab CI, Jenkins, etc. ). Voici un exemple de workflow pour générer les images OCI depuis un dépôt Github :
name: Generate Falco Artifacts
on:
push:
env:
OCI_REGISTRY: ghcr.io
jobs:
build-image:
name: Build OCI Image
runs-on: ubuntu-latest
permissions:
contents: read
packages: write
id-token: write
strategy:
matrix:
include:
- rule_file: config/rules/never-chmod-777.yaml
name: never-chmod-777
version: 1.0.0
steps:
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@f95db51fddba0c2d1ec667646a06c2ce06100226 # v3.0.0
- name: Log into registry ${{ env.OCI_REGISTRY }}
if: github.event_name != 'pull_request'
uses: docker/login-action@343f7c4344506bcbf9b4de18042ae17996df046d # v3.0.0
with:
registry: ${{ env.OCI_REGISTRY }}
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Checkout Falcoctl Repo
uses: actions/checkout@v3
with:
repository: falcosecurity/falcoctl
ref: main
path: tools/falcoctl
- name: Setup Golang
uses: actions/setup-go@v4
with:
go-version: '^1.20'
cache-dependency-path: tools/falcoctl/go.sum
- name: Build falcoctl
run: make
working-directory: tools/falcoctl
- name: Install falcoctl in /usr/local/bin
run: |
mv tools/falcoctl/falcoctl /usr/local/bin
- name: Checkout Rules Repo
uses: actions/checkout@v3
- name: force owner name to lowercase # Obligatoire pour les organisations / utilisateurs ayant des majuscules dans leur nom Github (ce qui est mon cas...)
run: |
owner=$(echo $reponame | cut -d'/' -f1 | tr '[:upper:]' '[:lower:]')
echo "owner=$owner" >>${GITHUB_ENV}
env:
reponame: '${{ github.repository }}'
- name: Upload OCI artifacts
run: |
cp ${rule_file} $(basename ${rule_file})
falcoctl registry push \
--config /dev/null \
--type rulesfile \
--version ${version} \
${OCI_REGISTRY}/${owner}/${name}:${version} $(basename ${rule_file})
env:
version: ${{ matrix.version }}
rule_file: ${{ matrix.rule_file }}
name: ${{ matrix.name }}
Pour ajouter une règle Falco, il suffit de créer le fichier dans le dépôt et indiquer les chemin, nom et version dans la matrice du workflow.
jobs:
strategy:
matrix:
include:
- rule_file: config/rules/never-chmod-777.yaml
name: never-chmod-777
version: 1.0.0
- rule_file: config/rules/search-for-aws-credentials.yaml
name: search-for-aws-credentials
version: 0.1.1
Je vous partage également la méthode de Thomas Labarussias qui consiste à profiter de la notation semver pour créer des images multi-tags (ex: 1.0.0, 1.0, 1, latest) :
- name: Upload OCI artifacts
run: |
MAJOR=$(echo ${version} | cut -f1 -d".")
MINOR=$(echo ${version} | cut -f1,2 -d".")
cp ${rule_file} $(basename ${rule_file})
falcoctl registry push \
--config /dev/null \
--type rulesfile \
--version ${version} \
--tag latest --tag ${MAJOR} --tag ${MINOR} --tag ${version}\
${OCI_REGISTRY}/${owner}/${name}:${version} $(basename ${rule_file})
env:
version: ${{ matrix.version }}
rule_file: ${{ matrix.rule_file }}
name: ${{ matrix.name }}
Ainsi, la version 1.0.0 aura pour tag latest, 1.0, 1 et 1.0.0. De cette manière, je peux spécifier dans ma configuration falcoctl le tag 1.0 qui sera équivalent à la dernière version de la branche semver : 1.0.x. (idem pour 1 qui sera équivalent à 1.x.x).
![]()
Créer son propre index d’artéfacts
Passons maintenant à la création de notre propre indexer pour référencer nos images OCI depuis falcoctl. Pour cela, nous avons besoin d’un serveur HTTP qui va exposer un fichier YAML contenant les informations des images OCI.
Pour ce faire, je vais simplement exposer mon index.yaml contenant les informations de mon image OCI ghcr.io/cuistops/never-chmod-777:1.0.0 dans un dépôt Github.
- name: cuistops-never-chmod-777
type: rulesfile
registry: ghcr.io
repository: cuistops/never-chmod-777
description: Never use 'chmod 777' or 'chmod a+rwx'
home: https://github.com/CuistOps/falco
keywords:
- never-chmod-777
license: apache-2.0
maintainers:
- email: quentinj@une-pause-cafe.fr
name: Quentin JOLY
sources:
- https://raw.githubusercontent.com/CuistOps/falco/main/config/rules/never-chmod-777.yaml
Ce fichier YAML est publiquement accessible via ce lien. Je vais ensuite l’ajouter en tant qu’index sur falcoctl.
$ falcoctl index add cuistops-security https://raw.githubusercontent.com/CuistOps/falco/main/config/index/index.yaml
2024-04-17 20:32:28 INFO Adding index name: cuistops-security path: https://raw.githubusercontent.com/CuistOps/falco/main/config/index/index.yaml
2024-04-17 20:32:28 INFO Index successfully added
Je peux voir les artéfacts disponibles dans mon indexer cuistops-security :
$ falcoctl artifact list --index cuistops-security
INDEX ARTIFACT TYPE REGISTRY REPOSITORY
cuistops-security cuistops-never-chmod-777 rulesfile ghcr.io cuistops/never-chmod-777
J’ajoute le follow vers mes règles en précisant uniquement le nom du package dans mon index.yaml, voici mon fichier complet de configuration falcoctl :
artifact:
follow:
every: 6h0m0s
falcoversions: http://localhost:8765/versions
refs:
- cuistops-never-chmod-777:1.0.0
driver:
type: modern_ebpf
name: falco
repos:
- https://download.falco.org/driver
version: 7.0.0+driver
hostroot: /
indexes:
- name: cuistops-security
url: https://raw.githubusercontent.com/CuistOps/falco/main/config/index/index.yaml
backend: "https"
Dès lors que je lance la commande falcoctl artifact follow, les règles never-chmod-777 sont installées automatiquement.
$ falcoctl artifact follow
2024-04-17 20:57:56 INFO Creating follower artifact: cuistops-never-chmod-777:1.0.0 check every: 6h0m0s
2024-04-17 20:57:56 INFO Starting follower artifact: ghcr.io/cuistops/never-chmod-777:1.0.0
2024-04-17 20:57:57 INFO Found new artifact version followerName: ghcr.io/cuistops/never-chmod-777:1.0.0 tag: 1.0.0
2024-04-17 20:58:00 INFO Artifact correctly installed
├ followerName: ghcr.io/cuistops/never-chmod-777:1.0.0
├ artifactName: ghcr.io/cuistops/never-chmod-777:1.0.0
├ type: rulesfile
├ digest: sha256:9fa17441da69ec590f3d9c0a58c957646d55060ffa2deae84d99b513a5041e6d
└ directory: /etc/falco
Avertissement
Durant mes expérimentations, j’ai rencontré un petit problème avec la configuration par défaut de falcoctl. Le registre falcosecurity ne fonctionnait pas correctement et n’était pas reconnu.
$ falcoctl index list
NAME URL ADDED UPDATED
C’est à cause d’une erreur dans la configuration indexes (/etc/falcoctl/config.yaml). En effet, le champ backend est obligatoire et doit être renseigné.
indexes:
- name: falcosecurity
url: https://falcosecurity.github.io/falcoctl/index.yaml
backend: "https" # <--- Ajouter cette ligne
J’ai proposé une petite PR pour corriger ce problème, mais en attendant que ce soit résolu (à la prochaine release, la v0.8.0), vous pouvez avoir le même incident.
Dans le chart Helm de Falco, il est possible de spécifier les indexers d’artéfacts à follow dans le values.yaml :
falcoctl:
config:
indexes:
- name: cuistops-security
url: https://raw.githubusercontent.com/CuistOps/falco/main/config/index/index.yaml
backend: "https"
Conclusion
Falco est un produit très intéressant qui m’a convaincu par sa simplicité d’utilisation et sa flexibilité.
J’émettrai tout de même une réserve sur l’obligation des artéfacts OCI que je trouve un peu lourde à gérer (l’usage d’un tag Git aurait été pratique, le fait de pouvoir mettre à jour le tag de l’OCI en suivant la norme semver aussi). Je regrette aussi le manque d’intégration avec Kubernetes pour l’ajout de règles, l’usage d’un CRD pour les règles aurait été un plus.
EDIT 2024-04-26 : Après discussion avec Thomas Labarussias, il m’a donné un exemple de Workflow Github pour faire un semblant de tracking semver avec les images OCI en donnant plusieurs tags à l’image. Cela permet de suivre les versions majeures, mineures et patchs d’une image OCI. De plus, il m’a expliqué que l’intégration avec un CRD pour Kubernetes était prévu dans une future version de Falco.
Si vous voulez approfondir le sujet, je vous invite également à consulter le talk Réagir à temps aux menaces dans Kubernetes avec Falco (Rachid Zarouali, Thomas Labarussias).
Merci d’avoir lu cet article, j’espère qu’il vous a été utile et vous a donné envie de tester Falco. Si vous le souhaitez, vous pouvez également soutenir mon travail en me payant un café via Ko-fi. Je remercie aussi Jérémy d’être présent pour me relire et donner son avis sur ce que j’écris.