Fault : injecter du chaos dans vos microservices

Il y a une loi non écrite dans notre métier mais bien connue : un service qui n’a jamais subi de panne en production tombera en production, au pire moment possible, de la façon la plus inattendue qui soit. À peu près de la même manière qu’un SRE qui n’a jamais causé d’incident finira inévitablement par en causer un.
En ce moment, je creuse pas mal le sujet du chaos engineering — une discipline qui consiste à injecter des pannes dans un système pour tester sa résilience. J’ai lu plusieurs livres, articles et études de cas sur le sujet. Peut-être que je sortirai un jour un talk sur ce sujet passionnant. En attendant, je voulais partager un outil que j’ai trouvé particulièrement intéressant : fault.
fault, c’est un proxy réseau qui s’intercale entre deux services et leur fait vivre des choses horribles. Réseau lent, erreurs HTTP, connexions avalées dans un trou noir. On va le mettre en pratique sur petite application démo pour voir comment il révèle les faiblesses de notre code et surtout comment y remédier.
Mais avant ça, je vais faire un récap rapide (et fortement incomplet) du chaos engineering pour ceux qui ne connaissent pas — et pour les autres, on passera directement à la partie pratique avec fault.
Le Chaos Engineering, c’est quoi ?
En 2011, Netflix avait une infrastructure tellement complexe que personne ne savait vraiment ce qui se passerait si un composant tombait. Leur réponse ? Ils ont créé le Chaos Monkey, un outil qui éteint aléatoirement des instances en production. Volontairement. Pendant les heures ouvrées.
Information
À savoir que ce n’est absolument pas Netflix qui a inventé le chaos engineering. En revanche, ils l’ont popularisé et démocratisé avec leur suite d’outils Simian Army — dont le Chaos Monkey est le plus célèbre.
L’idée paraît folle. Elle est pourtant assez logique : si votre système doit survivre aux pannes, autant le vérifier en conditions réelles et contrôlées, plutôt que de le découvrir à 3h du matin quand le téléphone sonne.
La différence avec les tests classiques ? Les tests vérifient que votre code fait ce qu’il est censé faire dans des conditions normales. Le chaos engineering vérifie ce que votre système fait quand l’infrastructure autour de lui dysfonctionne: réseau lent, service voisin qui ne répond plus, DNS capricieux.
Et si éteindre volontairement une instance pour tester le comportement est déjà un bon début, le chaos engineering vise à intégrer ces tests de partout dans le cycle d’une application : en local, dans les pipelines CI, dans les environnements de staging… voire directement en production pour les plus téméraires.. et ce de manière automatique et régulière.
Dans cet article, on va jouer le rôle du développeur qui teste son application.
Fault, le proxy du chaos
fault fait partie de la suite rebound — un ensemble d’outils de chaos engineering développé par rebound. C’est un proxy TCP qui s’intercale entre deux services et laisse passer le trafic normalement… jusqu’à ce que vous lui demandiez de faire des misères.
Ce qui le rend pratique : aucun agent à installer dans vos services, aucune modification de code. Le proxy s’installe simplement sur le chemin du trafic. Il peut injecter :
- Latence — ajouter X ms.
- Erreurs HTTP — des 500, 503… avec une probabilité configurable
- Blackhole — absorber tout le trafic sans jamais répondre
- Perte de paquets — le wifi de gare, en simulé.
- Limitations de bande passante — pour se souvenir de ce qu’était la 3G.
- Pannes DNS — résolutions qui échouent aléatoirement
Grosse plus-value : fault peut exporter ses métriques et traces vers un collecteur OpenTelemetry. Concrètement, chaque requête interceptée devient un span — avec la latence injectée, le type de panne, le statut de réponse. Ça permet de corréler directement les pannes injectées avec ce que vos dashboards Grafana/Jaeger/Tempo observent côté applicatif. On voit les effets du chaos dans les mêmes outils que ceux qu’on utilise en production, ce qui rend les tests beaucoup plus proches de la réalité.
fault run --proxy "9090=127.0.0.1:5001" --no-ui \
--with-latency --latency-mean 2000 \
--otel-collector-endpoint http://localhost:4317
L’application de démo : La Brûlerie
Pour illustrer tout ça, j’ai construit une petite appli e-commerce fictive : La Brûlerie, une boutique de cafés de spécialité en Flask.
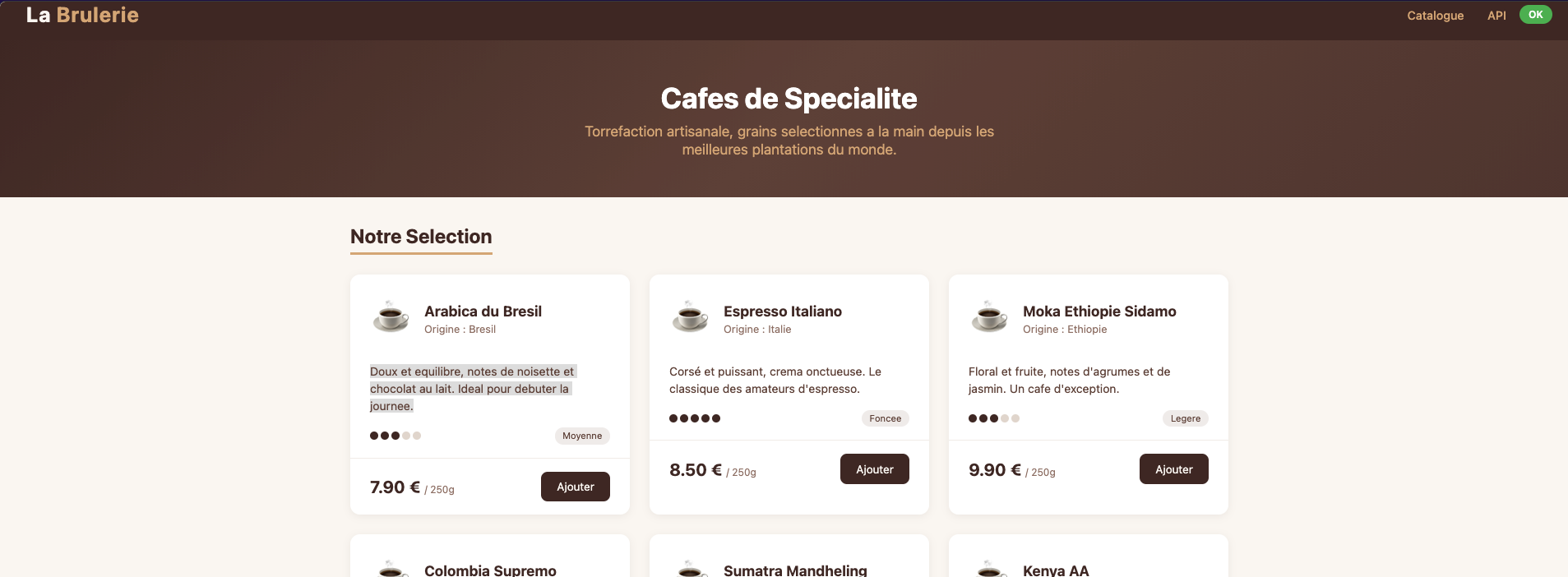 Architecture volontairement simple — deux services :
Architecture volontairement simple — deux services :
- shop (port 8080) : le frontend, affiche le catalogue et appelle
recopour les recommandations - reco (port 5001, dockerisé) : une API qui retourne 3 produits recommandés

shop appelle reco à chaque requête. Le proxy fault se place entre les deux.
Et dans ce code, il y a une bombe à retardement. Le savez-vous ?
def fetch_recommendations():
try:
r = requests.get("http://reco:5001/reco") # paramétrable via RECO_URL
return r.json(), "OK"
except Exception as e:
print(f"Erreur appel reco: {e}")
return [], "Degraded (No Reco)"
Bon, peu de suspense — la plupart des développeurs l’auront repérée. Mais justement, c’est là l’intérêt du chaos engineering : mettre en évidence des problèmes qu’on laisse passer sans y penser.
Commençons déjà par installer fault pour pouvoir faire nos tests.
# macOS ARM (Apple Silicon)
curl -sL -o fault https://github.com/rebound-how/rebound/releases/download/0.12.0/fault-cli-0.12.0-aarch64-apple-darwin
# Linux x86_64
curl -sL -o fault https://github.com/rebound-how/rebound/releases/download/0.12.0/fault-cli-0.12.0-x86_64-unknown-linux-gnu
chmod +x fault
sudo mv fault /usr/local/bin/fault
évidemment, pensez à vérifier les dernières releases sur GitHub pour avoir la version la plus récente.
Démarrage du POC
Trois terminaux (ou un multiplexer à la Tmux si vous aimez les bons tools 😇).
Terminal 1 — reco dans Docker :
docker compose up -d reco
curl http://localhost:5001/reco
# [{"badge":"Populaire","id":10,"name":"Espresso Intenso","price":6.9}, ...]
Terminal 2 — le proxy fault en mode passthrough :
fault run --proxy "9090=127.0.0.1:5001" --no-ui
9090=127.0.0.1:5001 : écouter sur le port 9090 et rediriger vers reco sur le 5001. --no-ui désactive l’interface TUI.
Terminal 3 — shop pointé vers le proxy :
RECO_URL="http://127.0.0.1:9090/reco" python3 poc-shop.py
On vérifie :
curl -w "Time: %{time_total}s\n" -o /dev/null -s http://localhost:8080/
# Time: 0.012s
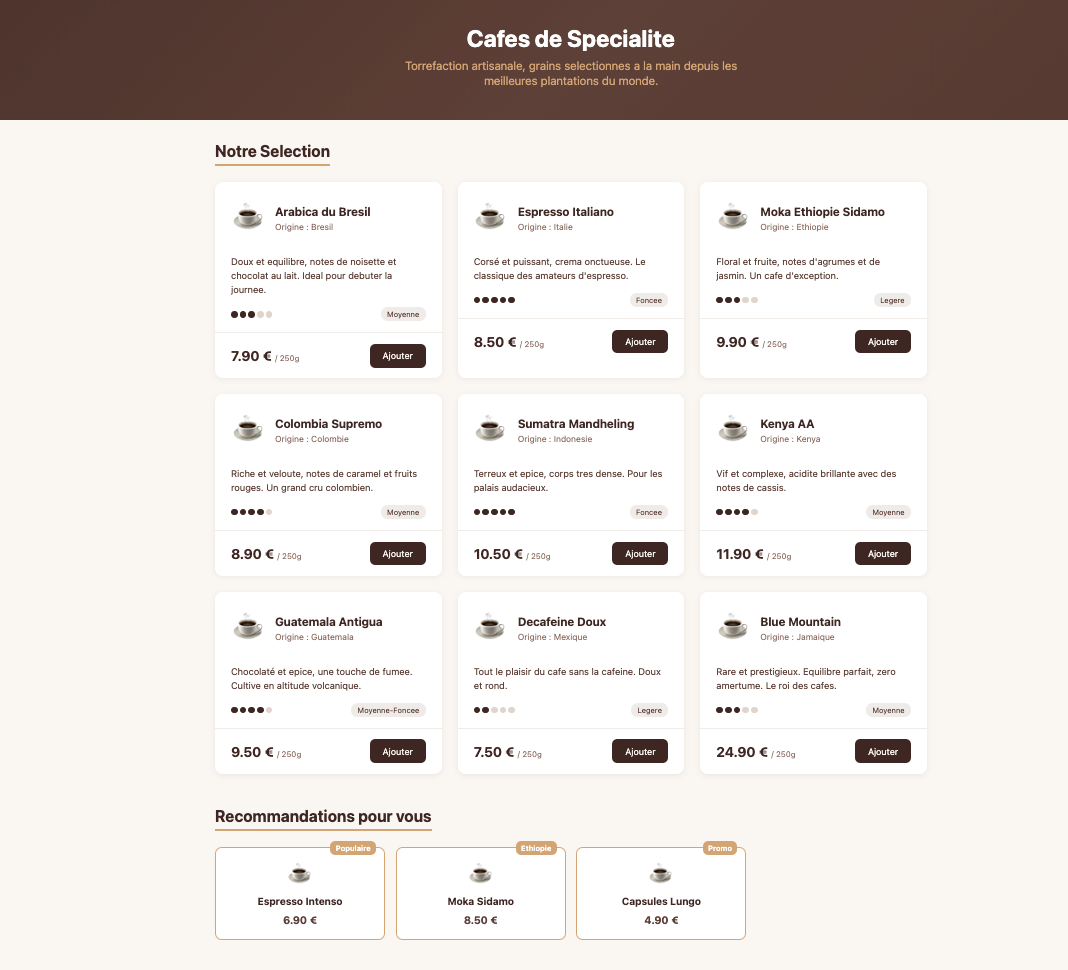
~12ms, tout fonctionne. place au chaos maintenant.
Les scénarios de chaos
On va tester de plusieurs manières notre service reco avec fault pour voir comment shop réagit — et surtout pour révéler la bombe à retardement du code. Nous allons y aller progressivement, en commençant par des pannes légères pour finir sur le scénario du blackhole.
Scénario 1 — Steady state (baseline)
Avant de réaliser un test de chaos, il est important d’avoir une baseline — un état de référence pour comparer les résultats. C’est ce qu’on va faire avec fault en mode passthrough : il laisse passer le trafic sans rien injecter.
Cette étape est un peu notre “témoin” pour comparer les résultats des scénarios suivants. Si on voit déjà des problèmes en baseline, ça veut dire que notre système n’est pas sain même sans chaos — et il faut régler ça avant de continuer.
En production, des toolkits comme litmus ou chaostoolkit permettent de définir ces steady-states (par ex. en se connectant sur le prometheus pour vérifier les métriques de santé) avant d’injecter les pannes.
fault run --proxy "9090=127.0.0.1:5001" --no-ui
curl -w "Time: %{time_total}s\n" -o /dev/null -s http://localhost:8080/
# Time: 0.011s ✅
~10ms. Badge “OK”. Notre référence.
Scénario 2 — Injection de latence (2 secondes)
fault run --proxy "9090=127.0.0.1:5001" --no-ui \
--with-latency --latency-mean 2000 --latency-stddev 500
curl -w "Time: %{time_total}s\n" -o /dev/null -s http://localhost:8080/
# Time: 2.387s ⚠️
~2 secondes de latence injectée sur chaque appel vers reco. La page se charge encore, mais le shop bloque pendant toute cette durée.
Comportement classique d’un service amont qui ralentit : toute la chaîne ralentit avec lui.
Scénario 3 — Erreurs HTTP 500 (50% de probabilité)
fault run --proxy "9090=127.0.0.1:5001" --no-ui \
--with-http-response --http-response-status 500 \
--http-response-trigger-probability 0.5
curl -s http://localhost:8080/product | jq -r '"\(.status) \(.recommendations | length)"'
# OK 3
# Degraded (No Reco) 0
Bonne surprise : le shop ne plante pas. Il affiche la page sans recommandations avec le badge “Degraded”. Le bloc except attrape l’erreur et retourne une liste vide — dégradation gracieuse.
On pourrait résoudre ça en utilisant un cache de recommandations, ou en retournant des recommandations par défaut. L’important c’est que le shop reste fonctionnel même si reco est cassé.
Scénario 4 — Blackhole (le pire cas)
fault run --proxy "9090=127.0.0.1:5001" --no-ui \
--with-blackhole
curl -w "Time: %{time_total}s\n" -o /dev/null -s --max-time 10 http://localhost:8080/
# Time: 10.003s 🔴
fault absorbe toutes les connexions sans jamais rien renvoyer. Du point de vue du shop, reco semble joignable — le TCP connect réussit — mais il n’envoie jamais de réponse.
Et le shop ? Il attend. Il attend encore. Il attendrait sans limites, parce qu’il n’y a aucun timeout sur l’appel HTTP. C’était ça, la bombe.
En production : workers Flask épuisés l’un après l’autre, connexions qui s’accumulent, et finalement plus personne ne répond — non pas parce que shop est cassé, mais parce qu’il est bloqué à attendre reco qui ne dira jamais rien.
Avertissement
C’est le scénario le plus dangereux. Un service qui tombe rend son voisin indisponible, qui rend son voisin indisponible… La panne se propage en cascade.
Résumons les résultats de nos scénarios :
| Scénario | Panne injectée | Temps de réponse | Impact |
|---|---|---|---|
| 1 — Baseline | Aucune | ~10ms | ✅ Normal |
| 2 — Latence | --with-latency --latency-mean 2000 | ~2s | ⚠️ Lent mais fonctionnel |
| 3 — HTTP 500 | --with-http-response --http-response-status 500 | ~10ms | ⚠️ Mode dégradé |
| 4 — Blackhole | --with-blackhole | ∞ (bloqué) | 🔴 Panne totale |
Le scénario 4 est celui qui nous interpèle vraiment et voyons le correctif.
Le fix : une ligne de code
# ❌ Fragile — bloquera indéfiniment si reco est lent ou inaccessible
r = requests.get("http://reco:5000/reco")
# ✅ Résilient — échoue proprement après 1 seconde
r = requests.get("http://reco:5000/reco", timeout=1)
Avec ce changement, scénario 4 :
curl -w "Time: %{time_total}s\n" -o /dev/null -s http://localhost:8080/
# Time: 1.003s ← timeout déclenché, page rendue en mode dégradé
Le shop répond en ~1 seconde avec le mode dégradé. L’exception requests.exceptions.Timeout est capturée par le except, le service retourne une liste vide, et la vie continue.
Remarque
Tout appel réseau doit avoir un timeout. Sans exception. La valeur exacte dépend de votre SLA, mais l’absence de timeout est toujours une erreur — même si le service appelé n’a jamais raté une requête de sa vie.
Pour aller plus loin : le circuit breaker (couper les appels vers un service qui échoue trop souvent) aurait été un bon complément à ce timeout.
Injection directement dans Kubernetes
Jusqu’ici on a fait tourner fault en local comme un proxy entre processus mais ça n’est pas très pratique et en big 2026 : on développe plutôt dans des conteneurs, c’est pour cela qu’il y a une commande fault inject kubernetes qui fait quelque chose de bien plus élégant : elle injecte le proxy directement dans le cluster, sans modifier une seule ligne de manifeste.
Comment ? En jouant sur le selector du Service ciblé.
fault inject kubernetes \
--ns chaos-demo \
--service reco \
--with-latency --latency-mean 2000 \
--duration 30s
Ce que fault fait derrière :
- Il déploie un Pod
reco-proxy(le proxy fault) dans le namespace - Il crée un Service
reco-backendqui pointe vers les vrais podsreco - Il modifie le selector du Service
recopour qu’il pointe versreco-proxy
kubectl get pods,svc -n chaos-demo
NAME READY STATUS RESTARTS AGE
pod/reco-57b95c5cdc-dbkmk 1/1 Running 0 3m8s
pod/reco-proxy-bx8wz 1/1 Running 0 9s ← injecté
pod/shop-6f97c7b8f5-bhsjq 1/1 Running 0 3m8s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
service/reco ClusterIP 10.99.114.245 <none> 5000/TCP ← selector → proxy
service/reco-backend ClusterIP 10.104.208.74 <none> 5000/TCP ← selector → vrais pods
service/shop ClusterIP 10.106.24.240 <none> 8080/TCP
Du point de vue de shop, rien ne change — il appelle toujours reco:5000. C’est le Service qui fait le détour via le proxy. Transparence totale et pas besoin de se baser sur des sidecars ou des configurations de réseau complexes.
Résultat avec latence injectée :
# Depuis un pod dans le cluster
curl -w "Time: %{time_total}s" -o /dev/null -s http://shop:8080/
# Time: 1.730s ⚠️ (contre ~10ms sans injection)
Et avec un blackhole :
fault inject kubernetes --ns chaos-demo --service reco --with-blackhole --duration 20s
curl -w "Time: %{time_total}s | Status: %{http_code}" -o /dev/null -s --max-time 5 http://shop:8080/
# Time: 5.002s | Status: 000 🔴 (bloqué jusqu'au timeout curl)
Une fois la durée écoulée, fault rollback automatiquement : le proxy Pod est supprimé, le Service reco-backend disparaît, et le selector du Service reco est restauré.
# Après rollback
curl -w "Time: %{time_total}s" -o /dev/null -s http://shop:8080/
# Time: 0.010s ✅
On profite alors de la puissance du chaos engineering directement dans Kubernetes, sans complexité supplémentaire. Pas besoin de redéployer les services, pas besoin de config spéciale — juste une commande fault inject et le chaos est là.
Scénarios automatisés et SLOs
fault inject et fault run c’est bien pour tester manuellement. Mais fault propose aussi une troisième commande : fault scenario, qui permet de définir des scénarios de charge et des SLOs sous forme de fichiers YAML — et de générer un rapport Markdown à la fin.
L’idée est simple : on fait tourner fault run (le proxy avec les fautes injectées) en parallèle, et on exécute fault scenario run pour lancer du trafic et mesurer si les SLOs sont respectés.
# reco-scenario.yaml
---
title: "La Brûlerie — SLOs sous latence injectée"
description: "Mesure les SLOs du service reco avec 2s de latence injectée."
items:
- call:
method: GET
url: "http://127.0.0.1:9090/reco" # → le proxy fault
meta:
operation_id: reco_with_latency
context:
upstreams: ["127.0.0.1:9090"]
faults: []
strategy: { mode: load, duration: 10s, clients: 3, rps: 3 }
slo:
- { type: latency, title: "P95 < 500ms", objective: 95, threshold: 500 }
- { type: latency, title: "P99 < 1s", objective: 99, threshold: 1000 }
- { type: error, title: "Erreurs < 1%", objective: 99, threshold: 1 }
expect: { status: 200 }
On lance les deux en parallèle :
# Terminal 1 — proxy avec 2s de latence
fault run --proxy "9090=127.0.0.1:5001" --no-ui \
--with-latency --latency-mean 2000 --latency-stddev 500
# Terminal 2 — scénario de charge + mesure SLOs
fault scenario run \
--scenario ./reco-scenario.yaml \
--report ./report.md
Et le rapport généré :
## Scenario: La Brûlerie — SLOs sous latence injectée
### GET http://127.0.0.1:9090/reco
Strategy: load for 10s with 3 clients @ 3 RPS
| Num. Requests | Num. Errors | Mean Latency (ms) | Total Time |
|---------------|-------------|-------------------|------------|
| 16 | 0 (0.0%) | 2003.72 | 11s |
| Latency Percentile | Latency (ms) |
|--------------------|--------------|
| p50 | 2003 ms |
| p95 | 3074 ms |
| p99 | 3074 ms |
| SLO | Pass? | Objective | Margin |
|--------------|-------|-----------------|-----------------|
| P95 < 500ms | ❌ | 95% < 500ms | Above by 2574ms |
| P99 < 1s | ❌ | 99% < 1000ms | Above by 2074ms |
| Erreurs < 1% | ✅ | 99% < 1% | Below by 1.0 |
Les SLOs de latence sont dans le rouge (2574ms et 2074ms au-dessus des seuils) mais les erreurs sont à 0 — exactement ce qu’on observe avec une latence pure. Le rapport est en Markdown, donc facile à intégrer dans une PR, un wiki ou une pipeline CI.
L’usage naturel en CI : faire tourner fault run pendant les tests d’intégration, lancer fault scenario run pour valider les SLOs, et échouer le build si un SLO n’est pas satifaisant. Pas besoin de lire des logs — le rapport dit tout.
Analyse LLM des résultats
Dur de faire des articles techniques sans parler de LLM aujourd’hui. Fault ne déroge pas à la règle : il intègre une couche d’agent qui peut être branchée sur les résultats des scénarios pour produire des analyses et suggestions de correction.
fault va encore plus loin avec une commande fault agent qui branche un LLM sur les résultats pour produire une analyse et des suggestions de correction.
Deux sous-commandes utiles :
scenario-review — prend le results.json généré par fault scenario run et demande au LLM d’analyser les échecs de SLOs, d’identifier les patterns de défaillance et de proposer des pistes de remédiation.
fault agent scenario-review \
--results ./results.json \
--role developer \
--report ./scenario-analysis.md
code-review — indexe le code source du projet (via embeddings + Qdrant), le croise avec les résultats du scénario, et génère des suggestions de fiabilité directement sur le code.
fault agent code-review \
--source-dir ./ecommerce \
--source-lang python \
--results ./results.json \
--report ./code-review.md
fault agent supporte OpenAI, Gemini, Ollama et OpenRouter. La partie code-review nécessite un serveur Qdrant pour stocker les embeddings du code source (utilisé pour la recherche sémantique).
# Qdrant en local
docker run -d -p 6333:6333 -p 6334:6334 qdrant/qdrant:v1.13.6
# Puis avec OpenAI
OPENAI_API_KEY=sk-... fault agent \
--llm-client open-ai \
--llm-prompt-reasoning-model gpt-4o-mini \
code-review \
--source-dir ./ecommerce \
--source-lang python \
--results ./results.json \
--index /tmp/fault-index.db \
--report ./code-review.md
Sur notre POC, voici ce que code-review a produit — en croisant les SLOs ratés du scénario et le code source indexé :
1. Add Retries with Exponential Backoff
Currently, the
fetch_recommendations()function makes a single request toRECO_URLwithout any mechanism to handle transient failures. Implementing a retry mechanism with exponential backoff can help recover from temporary issues.2. Set Request-Scoped Timeout
The code is marked as “fragile on purpose” with no timeout set for the
requests.get(). Adding a scoped timeout can prevent the application from hanging indefinitely.3. Extend Tracing and Metrics
Consider using a library like
opentelemetryorprometheus_clientto collect metrics or traces.4. Improve Error Handling
Handle specific exceptions (
ConnectionError,Timeout,HTTPError) rather than a generalException— cela permet un diagnostic plus fin en cas d’incident.
# Extrait du rapport code-review
def fetch_recommendations(max_retries=3, backoff_factor=0.5):
for attempt in range(max_retries):
try:
r = requests.get(RECO_URL, timeout=10) # timeout ajouté
r.raise_for_status()
return r.json(), "OK"
except (ConnectionError, Timeout) as e:
if attempt < max_retries - 1:
time.sleep(backoff_factor * (2 ** attempt)) # backoff exponentiel
continue
return [], "Degraded (No Reco)"
except HTTPError as e:
return [], "Degraded (No Reco)"
Le LLM repart du code réel et des métriques du scénario pour proposer des corrections ciblées. Ce n’est pas une analyse générique — il sait que reco_with_latency a raté ses SLOs de latence à 3s, et il cherche dans le code ce qui peut en être la cause.
À l’inverse d’un audit à partir du code source seul, il est directement aiguillé par les résultats de nos tests et pas juste fournir des best practices génériques.
Conclusion
Eh beh, ça faisait longtemps que je cherchais l’occasion de parler un peu de chaos engineering sur ce blog et je suis content d’avoir enfin trouvé un outil qui rend ça accessible et concret.
fault est vraiment sympa pour faire du chaos engineering de manière simple, sans complexité d’installation ou de configuration.
Je laisse la porte ouvert à faire des articles plus avancés ( pas forcément techniques ) sur le sujet du chaos engineering, les technologies, les théatres d’incidents célèbres, l’organisation de game-days… je commence à accumuler pas mal de matière sur le sujet (même si j’en fait pas encore dans un contexte de production) et je pense que ça peut être intéressant à partager.
En attendant, je vous encourage à me partager vos petites découvertes de chaos engineering, vos outils préférés, ou même vos anecdotes d’incidents qui auraient pu être évités avec un peu de chaos testing. C’est un sujet passionnant et il y a encore beaucoup à explorer !
Bon kawa chaos à tous ☕ !