NATS de A à Y

En septembre, je suis allé accueillir le petit nouveau de l’équipe Lucca dans les locaux à Nantes. Durant cette semaine, j’ai bien profité de notre super machine à café et j’ai remarqué que je n’étais pas le seul à l’apprécier.
Chaque matin, nous avions donc notre petite routine : café en arrivant, daily meeting, café après le daily. Le soucis que je souhaite vous exposer est durant ce second café où le succès de cette machine est le plus visible : il y a une queue de quelques minutes pour obtenir cet or noir.
J’ai alors décidé de réfléchir à un système pour diminuer cette attente avec une infrastructure redondée pilotant des cafetières.
Dans cet article, je vous propose qu’on réfléchisse ensemble à ce projet (ah oui, et c’est un prétexte pour parler de NATS).
Notre projet
Notre projet est similaire à une machine à café automatique comme on en voit partout dans les lieux publiques, mais nous visons une clientèle ayant des goûts un peu plus prononcés. Ainsi, nous proposerons de nombreux types de grains (et la présence de lait de vache ou de soja) et la possibilité de servir jusqu’à 5 cafés en même temps.
Nous devrons également respecter certaines règles pour assurer une disponibilité maximale :
- Pouvoir continuer à servir des cafés si une machine est en panne,
- Pouvoir suivre le stock de café,
- Pouvoir piloter les machines depuis un site internet.
Faisons un schéma de notre système :

Nous avons 5 cafetières connectées et pilotées par un contrôleur qui va recevoir les commandes. Ce même contrôleur va demander à un service si nous avons assez de café pour servir cette commande, la quantité de café en stock étant mise à jour à chaque fois qu’un café est servi.
Les interactions entre les services sont les suivantes :
- Coffee-shop envoie la requête à Controller ;
- Controller vérifie si la requête est correcte et possible (en contactant stock manager);
- Controller répond à Coffee-shop qui affiche un message de validation ;
- Controller envoie la requête aux machines à café ;
- La cafetière s’occupant de la commande va mettre à jour le stock via stock manager.
Interface utilisateur
Pour prendre les commandes, on désigne une interface simple (mais efficace) demandant :
- Le nom de la personne qui commande (façon Starbucks),
- La longueur du café,
- Le type de grain utilisé,
- La présence de lait,
- Le nombre de sucre (jusqu’à 3 max).
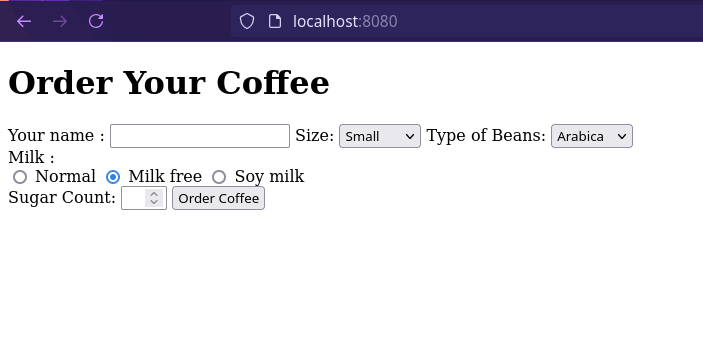
Bon… c’est pas très beau. Rajoutons un peu de CSS et une animation pour indiquer si la commande a bien été prise en compte.
On a fait du HTML/CSS, c’est bien, mais on ne va pas aller très loin si on s’arrête là : maintenant, notre commande doit bien attérir quelque part.
Nous allons faire un système à base de micro-services, mais commençons par expliquer cette notion.
Architecture en micro-services
Lorsqu’on développe une application, on est rapidement confronté au choix d’une architecture. Les deux possibilités sont :
- Le monolithe : avoir une application en un unique programme qui va s’occuper de toutes les fonctions présentes dans le cahier des charges. C’est le modèle le plus ‘simple’ à mettre en place et à déployer, ainsi que le plus optimisé (en terme de vitesse) mais possèdant de nombreuses contraintes :
- En cas d’erreur, l’application complète est en défaut ;
- Difficile à faire évoluer : il est complexe de mesurer l’impact d’un changement sur toute l’application ;
- Peu scalable : si on a un pic de charge sur une fonctionnalité précise, toute l’application est a re-déployer ;
- Développement complexe pour les grosses équipes : confier une fonctionnalité précise à une équipe externe n’est pas facile.
- Les micro-services : cette architecture permet de décomposer une application en plusieurs services qui communiquent entre eux, chaque service possèdant un rôle lié aux tâches qu’il doit accomplir. C’est un modèle complexe mais qui possède certains avantages comme le fait de pouvoir avoir plusieurs instances du même rôle pour des raisons de haute-disponibilité, ou pour répondre à un pic de charge sur un service précis. Il est également possible de mélanger les technologies et les langages de programmation pour peu que les services puissent toujours communiquer via le même canal (REST, Queuing…). Les inconvenients sont les suivants :
- Gestion des échanges : il est complexe de gérer les communications entre services ;
- Déboggage complexe : lorsqu’un problème intervient, il est difficile d’en trouver la cause parmis les services ;
- Redéveloppement de fonctionnalité : il est nécessaire de développer les mêmes fonctionnalités (logs, communications, tracing…).
Pour notre cas, je vais choisir l’architecture “micro-services” afin d’assurer la scalabilité et la haute disponibilité.
Les échanges entre les micro-services
Nous avons notre architecture, mais nous devons encore définir comment les services vont échanger entre eux. Il existe à nouveau deux méthodes :
- La méthode synchrone, façon “requête/réponse”. Un exemple assez simple est une requête REST : l’émetteur attend la réponse avant de continuer.
- La méthode asynchrone, un système de queuing (une file d’attente de message) dans lequel un programme va envoyer ses tâches, et d’autres vont consulter les actions à faire.

En dehors de l’asynchronicité, une différence majeure entre ces méthodes est qu’en modèle synchrone (e.g. via une API Rest) on se pose constamment la question “qui dois-je contacter pour cette requête?” pour définir l’adresse IP, le port et l’endpoint destinataire. Avec un broker (modèle asynchrone), on ne se pose pas la question de “qui”, mais plutôt de “quel est le sujet(topic) de ma requête?” (on parle de location transparency).
Par exemple, si ma requête concerne la création d’un utilisateur “quentin” dans l’application “coffee-lovers”, je peux envoyer un payload {'user': 'quentin', 'password':'Tasse2c4f3', 'fullname':'Quentin Joly', 'email': 'quentinj@une-pause-cafe.fr'} au sujet coffee-lovers.user, un service consommateur va alors écouter toutes les requêtes envoyées dans ce sujet et les appliquer.
Il est à noter que rien n’empêche d’avoir les deux systèmes (asynchrone et synchrone) dans une application, c’est d’ailleurs ce que nous allons faire.
Essayons de mettre en place ce système avec NATS.IO
Qu’est-ce que NATS ?
NATS.io est un système de messagerie open-source conçu pour des communications distribuées, légères et performantes. Il permet d’échanger des messages de manière asynchrone et en temps réel entre des applications, des services ou des appareils, en utilisant un modèle de publication/souscription ou de requête/réponse. NATS est ainsi souvent utilisé pour les microservices, l’IoT et les applications cloud-native.
Installer un serveur NATS
L’installation de NATS peut se faire de plusieurs manières (vous pouvez les trouver ici). Voici les deux méthodes que je vous recommande :
Via le script bash :
curl -sf https://binaries.nats.dev/nats-io/nats-server/v2@v2.10.14 -o install-nats.sh
chmod +x install-nats.sh
./install-nats.sh
mv nats-server /usr/bin/
Ou par la compilation du projet Golang :
go install github.com/nats-io/nats-server/v2@latest
Assurons directement une infrastructure pérenne en créant un cluster NATS redondé.
Créer un cluster
Je vais installer trois machines différentes, chacune ayant son propre serveur NATS :
# Server 1
nats-server -p 4222 --cluster_name nats-cluster --cluster nats://0.0.0.0:4248
nats-server -p 4222 -cluster nats://0.0.0.0:4248 -routes nats://192.168.128.52:4248,nats://192.168.128.53:4248 --cluster_name nats-cluster --server_name nats-01 -js
# Server 2
nats-server -p 4222 -cluster nats://0.0.0.0:4248 -routes nats://192.168.128.51:4248 --cluster_name nats-cluster
nats-server -p 4222 -cluster nats://0.0.0.0:4248 -routes nats://192.168.128.52:4248,nats://192.168.128.53:4248 --cluster_name nats-cluster --server_name nats-01 -js
# Server 3
nats-server -p 4222 -cluster nats://0.0.0.0:4248 -routes nats://192.168.128.51:4248,nats://192.168.128.52:4248 --cluster_name nats-cluster
nats-server -p 4222 -cluster nats://0.0.0.0:4248 -routes nats://192.168.128.52:4248,nats://192.168.128.53:4248 --cluster_name nats-cluster --server_name nats-01 -js
L’option -js active un paramètre nommé Jetstream, ne vous en préoccupez pas pour le moment.
Installer un client NATS
Maintenant que notre cluster NATS est Up and ready, nous allons installer la cli pour envoyer des requêtes. La méthode simple pour l’installer est de passer par le script bash suivant :
curl -sf https://binaries.nats.dev/nats-io/natscli/nats | sh
Bien sûr, je vous rappelle de toujours vous méfier des scripts que vous lancez à travers curl, vérifiez bien le contenu avant de lancer la commande.
nats server check connection -s 192.168.128.51:4222
OK Connection OK:connected to nats://192.168.128.51:4222 in 302.855572ms OK:rtt time 101.932065ms OK:round trip took 0.102134s | connect_time=0.3029s;0.5000;1.0000 rtt=0.1019s;0.5000;1.0000 request_time=0.1021s;0.5000;1.0000
Ainsi, pour envoyer un message, on peut utiliser la commande nats pub -s nats://192.169.128.51:4222 topic message, et pour un message en ‘Haute-disponibilité’, nous pouvons préciser plusieurs serveurs destinataires (l’un d’entre eux recevra forcément le message).
nats pub -s "nats://192.168.128.51:4222,nats://192.168.128.52:4222,nats://192.168.128.53:4222" hello world
Le fait de devoir préciser les 3 serveurs dans notre commande la rend très longue, on va vite y remédier en créant un “contexte” (qui gardera en mémoire ce paramètre) :
nats context add coffee-shop
nats context edit coffee-shop
nats context select coffee-shop
Une fois le contexte sélectionné, nous n’avons plus besoin de préciser les IPs des noeuds du cluster.
Premiers échanges
Comme vous le savez, NATS fonctionne avec un système de ‘publication’ (pub) et de souscription (sub). Les clients destinataires vont demander à recevoir les messages d’un ’topic’ et les clients transmetteurs vont envoyer des informations dans des topics précis.
# Terminal 1
nats subscribe ">"
# Terminal 2
nats pub hello world
Si tout se passe bien, nous devrions voir le message “world” dans le topic “hello” sur le terminal qui s’est sub.

Information
En tant que client “sub”, il est possible d’utiliser des wildcards pour définir une plage de topic sur lesquels nous écoutons les messages entrants. Voici les deux différents wildcards disponibles :
>= Wildcard, on peut l’utiliser avec un prefix (e.g. “coffee.>”)*= Wildcard pour une section du topic (e.g.coffee.*match aveccoffee.orderetcoffee.machinemais pascoffee.machine.krups_01)
Échanger un message en asynchrone entre deux services
Maintenant, on entre dans le vif du sujet ! Nous allons commencer à développer les premiers composants de notre infrastructure. Bien sûr, notre premier besoin reste d’échanger des messages entre deux codes.
Dans cette partie, on va POC le fait d’échanger une instruction entre deux services : controller et coffee-maker-{id} représentant une machine à café connectée.
Objectif number one : obtenir un moyen fiable d’envoyer une requête vers une cafetière.
Créons donc un premier code en Golang pour envoyer une information dans le topic coffee.
package main
import (
"log"
"github.com/nats-io/nats.go"
)
func main() {
nc, err := nats.Connect(os.Getenv("NATS_URL"))
if err != nil {
log.Fatal(err)
}
defer nc.Close()
subj, msg := "coffee.request", []byte("{\"size\":\"medium\", \"bean_type\":\"Arabica\", \"name\":\"Quentin\", \"milk\": \"free\", \"sugar_count\":"2" }")
nc.Publish(subj, msg)
nc.Flush()
if err := nc.LastError(); err != nil {
log.Fatal(err)
} else {
log.Printf("Published [%s] : '%s'\n", subj, msg)
}
}
Ce code est une première introduction au SDK NATS, un équivalent de la cli serait nats pub coffee.request '{"size": "medium", "bean_type":"Arabica","name":"Quentin","milk":"free","sugar_count":"2"}.
Maintenant, créons le service recevant la requête, jouant le rôle de la machine à café.
package main
import (
"fmt"
"log"
"os"
"github.com/nats-io/nats.go"
)
func main() {
nc, err := nats.Connect(os.Getenv("NATS_URL"))
if err != nil {
log.Fatal(err)
}
defer nc.Close()
if _, err = nc.Subscribe("coffee.*", func(m *nats.Msg) {
fmt.Println("New order received")
fmt.Println(m.Data)
})
err != nil {
log.Fatal(err)
}
// wait forever
select {}
}
En lançant ces deux applications, nous venons de permettre à deux programmes de communiquer ensemble.

Maintenant… il y a un soucis avec ce code, un énorme soucis même. Lançons l’équivalent de ce code via le client NATS pour expliquer le problème.
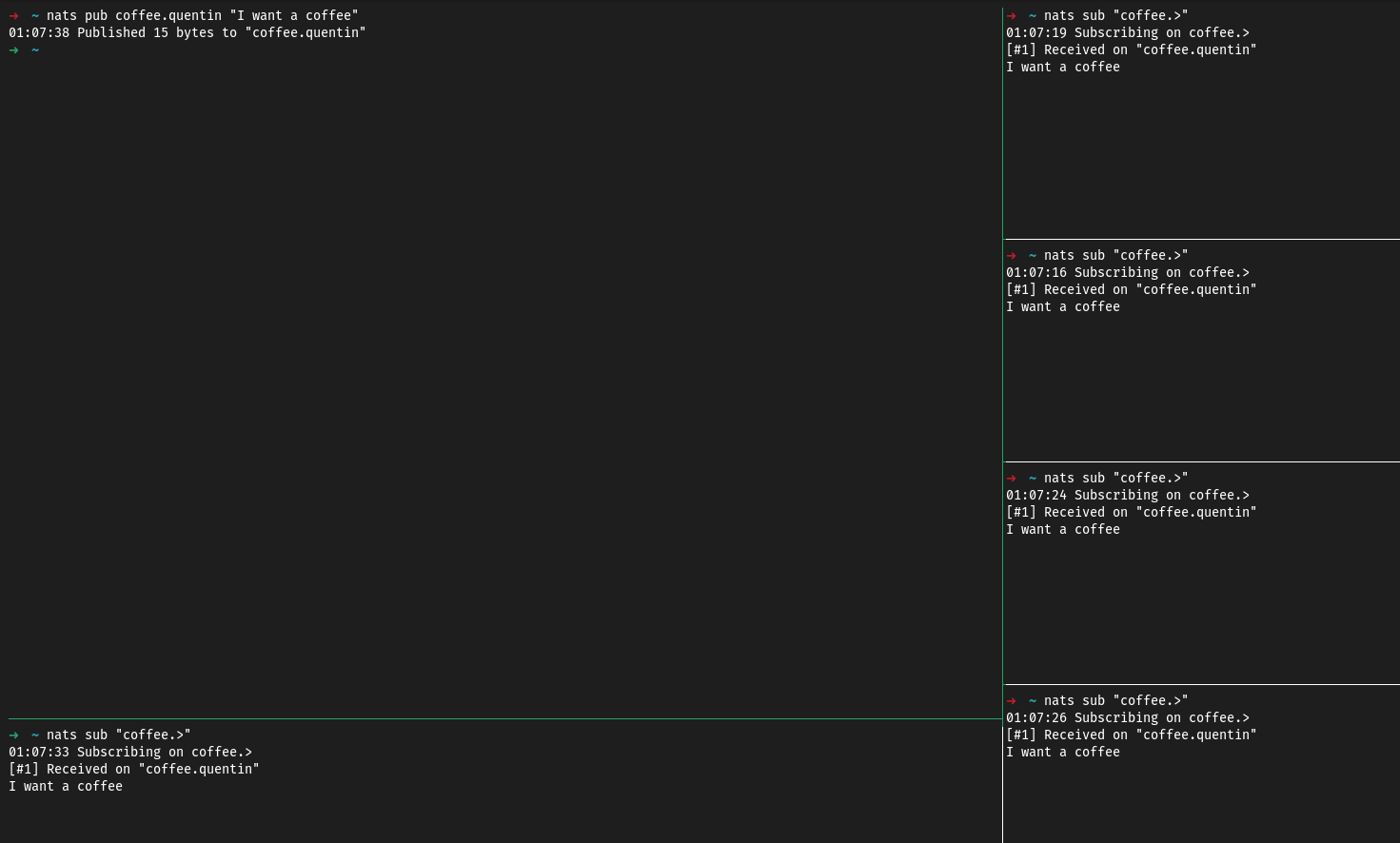
Pour résumer, les cinq cafetières étant toutes des clients indépendants et n’ayant aucun lien, elles reçoivent toutes les mêmes informations. Si c’était une commande de café, il y aurait 5 préparations.
Pour arranger ça, on supprime l’usage de nc.Subscribe pour le remplacer par nc.QueueSubscribe, une instruction dans laquelle NATS ne va transmettre la tâche qu’à un seul membre connecté de ce groupe. Je défini alors un nom de groupe coffee-maker.
package main
import (
"fmt"
"log"
"os"
"github.com/nats-io/nats.go"
)
func main() {
nc, err := nats.Connect(os.Getenv("NATS_URL"))
if err != nil {
log.Fatal(err)
}
defer nc.Close()
if _, err := nc.QueueSubscribe("coffee.>", "coffee-maker", func(m *nats.Msg) {
fmt.Println("New order received")
fmt.Println(string(m.Data))
})
err != nil {
log.Fatal(err)
}
select {}
}
Toutes les machines démarrant ce code vont rejoindre le groupe nommé “coffee-maker” écoutant les topics coffee.>. Grâce à cette nouvelle méthode, seul un membre du groupe va recevoir l’instruction envoyée à ce topic.
Ouf, il n’y a plus aucun risque que plusieurs cafetières se lancent pour une seule commande, le portefeuille du gérant peut dormir en paix.
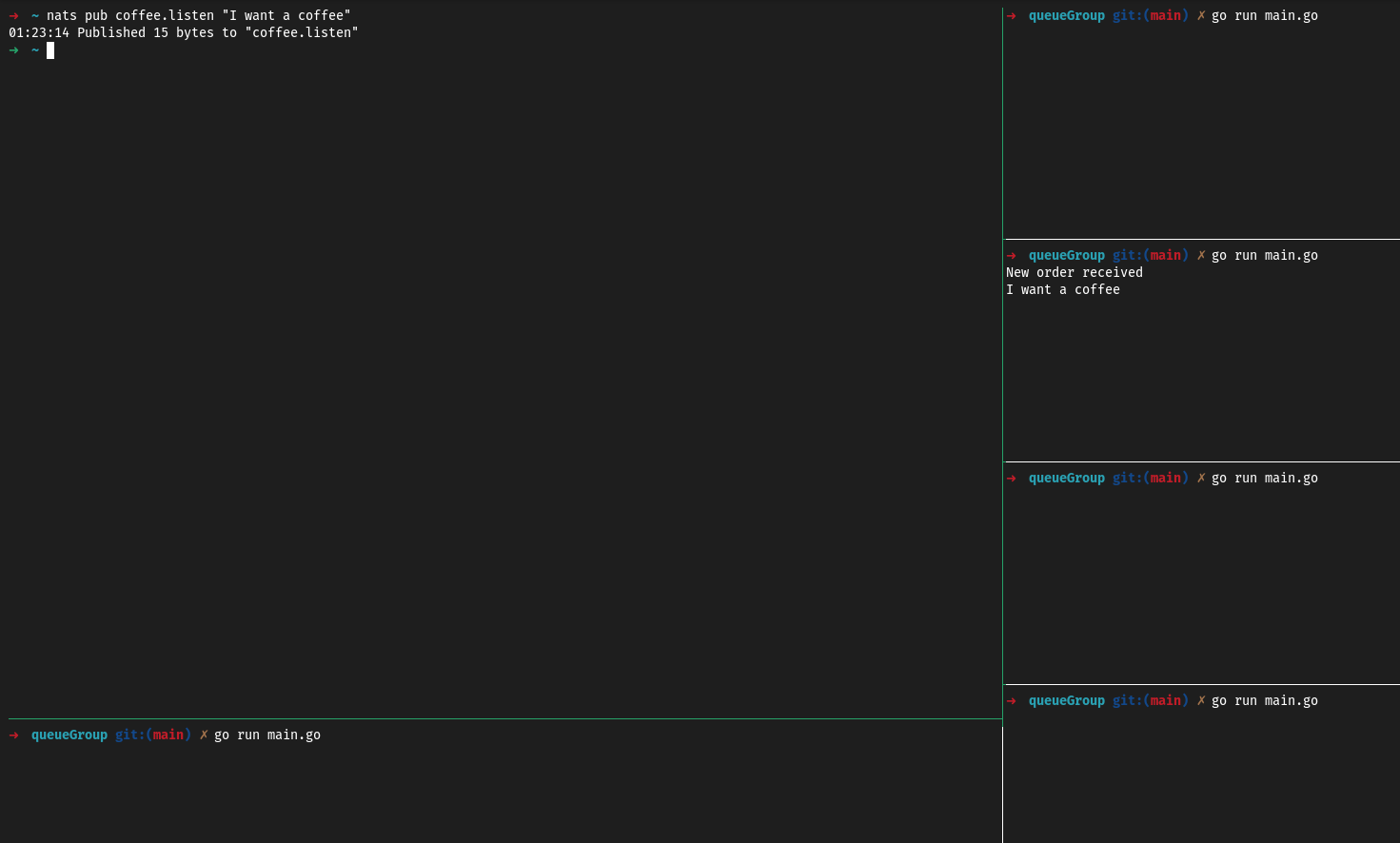
Mais il y a quelque chose qui me chiffone… Y’a t’il de la persistance dans les messages envoyés à la pile ? Les messages sont-ils transmis directement ou consommés comme une pile de tâche ?
Pour tester ça, faisons une expérience. Je vais éteindre mon service ‘machine à café’, envoyer une instruction et rallumer ce service.
Si cela fonctionne, la machine sera en mesure de traiter la requête en vérifiant les tâches empilées. Si cela ne fonctionne pas, ça veut dire qu’il n’y a aucune persistence dans notre file d’attente et que nous ne faisons que transférer un message.

Nous avons un problème ici : si les cafetières ne sont pas allumées durant l’envoi de la tâche, l’information est perdue et le café n’est jamais lancé.
On retourne à la documentation en cherchant une solution !
Jetstream - la persistence des tâches
Jetstream est le nom que l’on donne à un ensemble de fonctionnalités intégrées à NATS. On utilise Jetstream dès que nous avons un minimum de persistence et des contraintes de haute-disponibilité. Jusqu’à présent, nous utilisions NATS-CORE qui ne fait “que” transmettre un message d’un point A vers un point B (comme le ferait un MQTT).
Jetstream, lui, va plutôt agir comme une boîte mail partagée. Nous allons envoyer les tâches à exécuter, celles-ci seront sauvegardées dans le dossier INBOX et dès qu’un agent se connecte à l’adresse mail, il peut marquer comme “lu” le mail, indiquant aux autres employés que la tâche est déjà prise en charge. Pour revenir à NATS, les serveurs vont ainsi garder en mémoire certaines informations consultables par les services le demandant.
Pour vérifier si votre endpoint NATS possède le Jetstream activé, vous pouvez taper la commande nats account info.
$ nats account info
Account Information
User:
Account: $G
Expires: never
Client ID: 82
Client IP: 192.168.128.33
RTT: 100ms
Headers Supported: true
Maximum Payload: 1.0 MiB
Connected Cluster: nats-cluster
Connected URL: nats://192.168.128.53:4222
Connected Address: 192.168.128.53:4222
Connected Server ID: ND7RRDG36S2JT7TCHUHJJBMPOFWLTWQAABQMIA6P3V3FMKLDTYX5ZKO6
Connected Server Version: 2.10.14
TLS Connection: no
No response from JetStream server
No response from JetStream server indique que Jetstream n’est pas supporté.
Pour l’activer, il nous faut rajouter l’argument -js dans les commandes nats-server de nos instances NATS (si vous aviez utilisé les mêmes commandes que moi, jetstream devrait déjà être activé).
Pour la même commande, nous devrons avoir des détails concernant Jetstream :
JetStream Account Information:
Account Usage:
Storage: 0 B
Memory: 0 B
Streams: 0
Consumers: 0
Account Limits:
Max Message Payload: 1.0 MiB
Tier: Default:
Configuration Requirements:
Stream Requires Max Bytes Set: false
Consumer Maximum Ack Pending: Unlimited
Stream Resource Usage Limits:
Memory: 0 B of Unlimited
Memory Per Stream: Unlimited
Storage: 0 B of Unlimited
Storage Per Stream: Unlimited
Streams: 0 of Unlimited
Consumers: 0 of Unlimited
Maintenant que nous avons activé les streams, on peut essayer d’en créer un pour tester les fonctionnalités.
nats stream add
[cluster] ? Stream Name test
[cluster] ? Subjects coffee.tests
[cluster] ? Storage file
[cluster] ? Replication 3
[cluster] ? Retention Policy Limits
[cluster] ? Discard Policy Old
[cluster] ? Stream Messages Limit -1
[cluster] ? Per Subject Messages Limit -1
[cluster] ? Total Stream Size -1
[cluster] ? Message TTL -1
[cluster] ? Max Message Size -1
[cluster] ? Duplicate tracking time window 2m0s
[cluster] ? Allow message Roll-ups No
[cluster] ? Allow message deletion Yes
[cluster] ? Allow purging subjects or the entire stream Yes
Il se nomme test et sera effectif sur le sujet coffee.tests.
Consultons une première fois le contenu du stream :
nats stream view test
18:17:10 Reached apparent end of data
Logiquement, il n’y a aucun message. Envoyons maintenant quelques informations à stocker dans le stream :
nats pub coffee.test --count 3 "{{Count}} - {{ID}}"
18:19:27 Published 26 bytes to "coffee.test"
18:19:27 Published 26 bytes to "coffee.test"
18:19:27 Published 26 bytes to "coffee.test"
Via les fonctionnalités NATS.CORE, un message non-consommé est un message perdu, mais grâce à Jetstream nous devrions pouvoir voir les messages que nous venons d’envoyer.
nats stream view test
[11] Subject: coffee.test Received: 2024-08-26T18:19:26+02:00
1 - DzMgDtKaHvsEOx5FuR2L1u
[12] Subject: coffee.test Received: 2024-08-26T18:19:27+02:00
2 - DzMgDtKaHvsEOx5FuR2L5F
[13] Subject: coffee.test Received: 2024-08-26T18:19:27+02:00
3 - DzMgDtKaHvsEOx5FuR2L8a
18:22:11 Reached apparent end of data
Ainsi, nous venons de voir l’importance de Jetstream dans NATS et la notion de persistence dans notre queue.
Et qu’est-ce que ça donne en Golang ? Voyons comment créer un stream :
// Create the stream
js, _ := jetstream.New(nc)
ctx, _ := context.WithTimeout(context.Background(), 10*time.Second)
subject := "coffee.test"
cfgStream := jetstream.StreamConfig{
Replicas: 3,
Name: streamName,
Subjects: []string{subjects},
Storage: jetstream.FileStorage,
Retention: jetstream.WorkQueuePolicy,
}
js.CreateOrUpdateStream(ctx, cfgStream)
Pour consommer les messages dans le stream, c’est un peu différent, nous devons nous définir comme “consumer” auprès de NATS. En utilisant le même nom de consumer sur nos différents clients pour que NATS agisse automatiquement comme un LoadBalancing (comme avec les workQueues que nous avons vu précédemment).
Nous avons également accès à de nouvelles instructions pour définir si un message est en cours de traitement, s’il a été traité, s’il est invalide, etc :
Ack(), le message est traité et il ne peut être retiré de la pile ;inProgress()qui indique que le message est en cours (et que nous prenons du temps pour le traiter). Cette instruction peut être appelée autant de fois que nécessaire (pour peu qu’on respecte le MaxAge si notre mode de réplication en a besoin) ;Nack(), le consumer ne peut temporairement pas traiter ce message (il faut le relivrer) ;Term(), le message n’est pas valide, il faut le retirer de la pile.
Voici un exemple de comment une machine à café va agir face à un message :
cfgConsu := jetstream.ConsumerConfig{
Name: consumerName,
FilterSubject: subjects,
Durable: consumerName,
}
cons, _ := js.CreateConsumer(ctx, cfgStream.Name, cfgConsu)
cons.Consume(func(msg jetstream.Msg) {
fmt.Printf("New message from %s : %s ", msg.Subject(), string(msg.Data()))
msg.InProgress() // Inform that we're handling this message (get more time)...
// Process...
msg.Ack() // Inform that this message has been successfully handled
})
Information
J’en profite pour vous faire un petit topo sur les différents types de rétention de streams :
LimitsPolicy, la suppression se fait lorsqu’on atteint les limites de stockage du streams (nombre de message par subject, TTL des messages) ;InterestPolicy, si aucun consumer n’est connecté, les messages sont automatiquement supprimés (ou si un message est Ack par tous les consumers intéressées par le subject) ;WorkQueuePolicy, on réparti les tâches dans une queue, le message est supprimé après un Ack ou un Term. Chaque subject ne peut avoir qu’un consumer (mais plusieurs clients par consumer).
Mais alors, qu’est-ce que ça donne ?
Je vais mettre quatre cafetières en service et lancer une première salve de commandes où chaque café prend 500ms (rêvons un peu…). Nous aurons une machine de spare “au cas où” le pic de charge serait trop élevé (et ça sera le cas).
Que se passe-t’il une tâche échoue ? Il y a plusieurs cas de figure :
- Le message a été livré à un consumer, dans ce cas, la variable de configuration
AckWaitdu consumer intervient et défini le temps avant que NATS ne relivre ce message à un client ; - Le message est en
InProgress(), cela ‘reset’ le timer duAckWaità chaque appel. Une fois que c’est terminé : le message est redélivré s’il n’a pas étéAck; - Le consumer gère le cas où il n’arrive pas à traiter un message et renvoie un
Nack(), le message est directement redélivré. (à ne pas confondre avec unTerm()qui indique que le message n’est pas traité et est supprimé).
Si j’introduis 10% de chances pour qu’un café échoue, voici ce que ça donne :
Dès qu’un message est marqué comme Nack (à chaque fois qu’il y a un ‘failed’), la requête est automatiquement relivrée.
Côté machine à café, c’est presque terminé, alors attaquons-nous à un nouveau front.
Requête synchrone
Vous n’avez pas mal lu, nous allons bien faire des requêtes synchrones dans notre broker. En effet, il y a des interactions entre nos services qui nécessitent une attente de réponse.
Ces intéractions, les voici :

Le composant “routes” (site internet) doit pouvoir accuser réception de la demande du client (et même mieux, savoir si la commande est possible) tout comme les machines à café doivent pouvoir s’assurer que le stock a bien été mis à jour avant de faire un nouveau café.
Pour cela, nous avons deux options :
- Utiliser un modèle de transmission spécifique aux échanges synchrones (c.a.d. basculer sur du http/gRPC).
- Utiliser les “requêtes” dans NATS.
J’ai dit que NATS était au centre de nos échanges.. alors il le sera vraiment : partons pour la seconde option !
Mais d’abord, qu’est-ce qu’une requête avec NATS ?
Jusqu’à présent, lorsque nous envoyions un message via nats pub, nous n’attendions pas de réponse (et nous ne pouvions en avoir), mais dans un système PUB/SUB, comment recevoir une réponse ?
En réalité, c’est assez simple, nous (emetteur) allons envoyer un message en indiquant que nous attendons une réponse dans un topic “éphémère” (dont la durée de vie est limitée à celle du client).

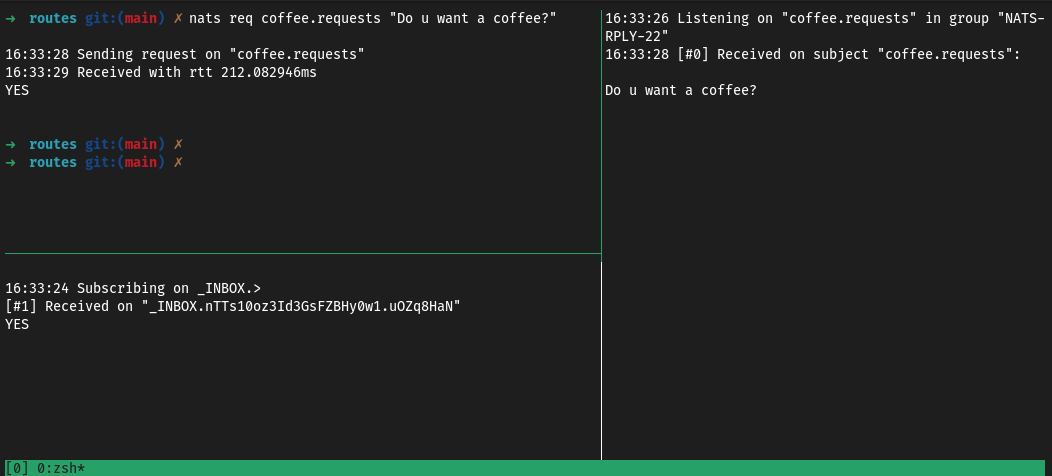
Créons un consumer temporaire via nats reply (une commande pour répondre aux messages reçu dans un topic).
# Terminal 1
nats reply coffee.requests "YES"
# Terminal 2
nats req coffee.requests "Do u want a coffee?"
Le terminal 2 recevra “YES” comme réponse.
Si on s’amuse également à écouter ce qui se passe via un nats sub coffee.requests, on découvre ceci :
[#1] Received on "coffee.requests" with reply "_INBOX.DPDw4I48qhNhtWsQ8ZOkmL.ygr1GWEF"
Cela nous indique que le message envoyé dans coffee.requests précise qu’il attend une réponse dans un topic éphémère qu’est "_INBOX.DPDw4I48qhNhtWsQ8ZOkmL.ygr1GWEF.
En connaissant ça, nous pouvons implémenter un code entre les composants routes et controller.
Déjà, admettons que les valeurs envoyées seront toujours en JSON (pour faciliter la transmission).
Ainsi, lorsque routes transmet les commandes reçues à controller, voici un exemple de message envoyé :
{"size":"big","bean_type":"mixed","milk":"free","name":"Quentin","sugar_count":"1"}
La réponse de controller se fait également en Json (cette réponse permettra d’afficher un message de validation à l’utilisateur).
{"status":"success","message":"The coffee has been successfully scheduled"}
Comment transférer ces messages ? Par une Request/Reply, pardi !
La requête s’initie de cette manière (coté routes) :
rep, err := nc.Request(subject, jsonData, 2*time.Second)
if err != nil {
fmt.Println(err.Error())
return response, err
}
err = json.Unmarshal(rep.Data, &response)
if err != nil {
return response, errors.New("can't unmarshall response from controller")
}
Du coté du destinaire, on peut appeler un msg.Respond contenant la réponse à envoyer dans le topic éphémère
Donc les communications en synchrone seront :
- le site vers le controleur,
- le controleur vers le gestionnaire de stock,
- les cafetières vers le gestionnaire de stock.
Cette souplesse d’architecture nous permet de ne pas avoir à intégrer des topics dédiés aux réponses et de ne pas avoir à gérer des timeouts, NATS s’occupe de tout.
Le KV store
Voici quelques heures que je m’amuse à me commander des cafés (malheureusement, ces machines à cafés n’existent toujours pas…) et j’ai déjà une remarque à faire au développeur (toujours moi). Faire cinq cafés en même temps, c’est très pratique pour assurer un bon débit, mais il n’empêche que s’il y a de nombreuses personnes devant moi, je vais quand même faire la queue (ironique pour un article sur du queueing) et attendre que ma commande arrive.
Je sais qu’un déploiement de Kubernetes me prend ~10min, si j’en profite pour aller me prendre un café et que je dois attendre 5min pour obtenir ma boisson chaude, je perds beaucoup de temps sur ma pause.
Bref, ce serait cool de pouvoir prévoir le temps que prendra ma commande (en gros, un ETA).
Pour cela, considérons que la confection d’un café dure ~1 minute. Il suffit d’appliquer la formule nb_commandes * 1m / nb_machines pour obtenir le temps d’attente.
On connaît déjà le nombre de machines, il ne reste qu’à obtenir le nombre de commandes en requétant NATS pour obtenir le nombre de messages en attente d’un “Ack” sur le stream. Cette information est directement contenue dans l’object cons (consumer) des cafetières.
consInfo, err := cons.Info(context.TODO())
if err != nil {
log.Fatal("Error getting consInfo: ", err)
}
// We subtract the order we're currently handling
numPendingOrders := consInfo.NumAckPending - 1
fmt.Printf("pending orders: %d\n", numPendingOrders)
Notre nouvelle problématique est que cette information est connue des machines à cafés, mais pas du composant gérant l’interface web (puisque ce sont les utilisateurs les destinataires de cette information, nous devons l’afficher sur le site).
Pour cela, nous devons obtenir un moyen de transférer une valeur entre nos composants. Ça, on le fait depuis le début en envoyant des messages d’un composant à un autre, mais qu’en est-il d’une simple “variable” (pas de Ack, la valeur doit directement être lue, et doit être mise à jour en temps réel).
Pour ce faire, NATS propose un système de KV (key-value) store dans lequel on peut stocker de simples variables. Ainsi, n’importe quel composant peut se brancher au cluster et consulter des données (sans devoir créer un jetstream, gérer la rétention ou devoir attendre de recevoir l’information).
const (
kvBucket = "orders-values"
kvVar = "orders.pending"
)
//...
kv, err := js.CreateKeyValue(ctx, jetstream.KeyValueConfig{
Bucket: kvBucket,
})
if err != nil {
log.Printf("can't init kv store: %w", err)
}
_, err = kv.Put(context.TODO(), kvVar, []byte(fmt.Sprint(numPendingOrders)))
if err != nil {
log.Printf("Error saving orders pending to kv: %w", err)
}
Coté serveur web, je vais passer d’une source html statique à une template qui sera exécutée lorsque l’utilisateur consulte le formulaire.
http.HandleFunc("/index", func(w http.ResponseWriter, r *http.Request) {
var numberOfPendingOrders int
kvValuePendingOrders, err := kv.Get(context.Background(), "orders.pending")
if err != nil {
// If the key doesn't exist or we can't get the value, we set the number of pending orders to -1
// This error is not fatal, we can still display the page
numberOfPendingOrders = -1
} else {
numberOfPendingOrders, _ = strconv.Atoi(string(kvValuePendingOrders.Value()))
}
tmpl, err := template.ParseFiles("./src/index.html")
if err != nil {
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
return
}
var waitingTime string
if numberOfPendingOrders != -1 {
// Each coffee take about 1 minute
waitingTime = strconv.Itoa(numberOfPendingOrders/concurrency) + "min"
} else {
waitingTime = "Unknown"
}
data := struct {
WaitingTime string
}{
WaitingTime: waitingTime,
}
err = tmpl.Execute(w, data)
if err != nil {
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
return
}
}
Dans le fichier ./src/index.html, je peux consommer la variable .WaitingTime en utilisant la syntaxe proposée par GoTemplate, voici ce que ça donne :
<footer style="text-align: center; margin-top: 20px;">
Waiting time : {{.WaitingTime}}
</footer>
Une fois le code lancé, nous pouvons voir que la valeur est bien affichée sur le site.
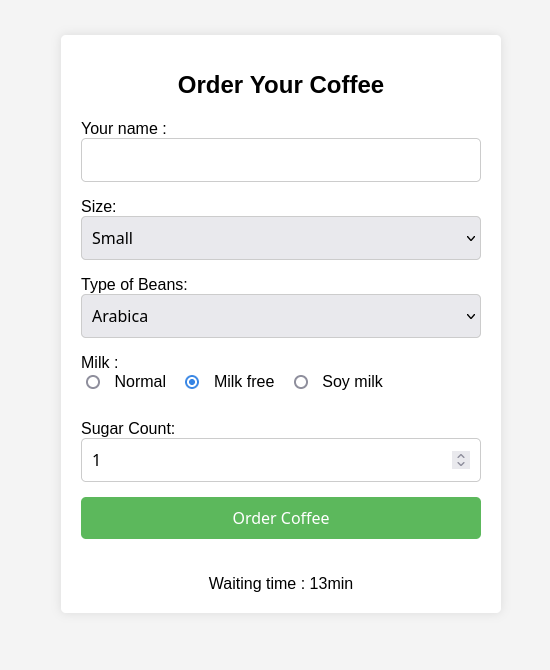
À l’avenir, nous pourrons également envisager d’utiliser le KV pour régler la quantité de café par taille, ou même remplacer la base de données (actuellement utilisée pour stocker la quantité de grain).
Petite note, j’aurais aimé calculer le nombre de machines à café depuis le code, mais je n’ai pas l’impression que cette information soit disponible dans le SDK.
L’authentification
Je vous l’ai dit au début de l’article : avoir son café le matin, c’est important. Je ne voudrai surtout pas que quelqu’un accède à mon système pour empêcher les gens de commander des cafés ou pire : vider les stocks.
Pour cela, plusieurs mécanismes peuvent être utilisés pour s’authentifier sur un serveur NATS :
- Le chiffrement (mTLS) ;
- Un simple ’token’ ;
- Un couple login/password ;
- Un certificat ed25519.
Nous allons configurer de l’authentification pour chaque composant ainsi que pour les serveurs NATS entre eux.
Commençons par notre cluster !
Authentifier les membres du cluster
Nous allons devoir générer un fichier de configuration pour chaque membre du cluster NATS. Nous pouvons également en profiter pour se débarasser des arguments au démarrage de nats-server. Pour rappel, lorsqu’on démarre un serveur dans notre cluster, cela ressemble à ça :
nats-server -p 4222 -cluster nats://0.0.0.0:4248 -routes nats://192.168.128.52:4248,nats://192.168.128.53:4248 --cluster_name nats-cluster --server_name nats-01 -js
Commande que nous pouvons simplifier en ce fichier de configuration :
server_name=nats-01
listen=4222
cluster {
name: nats-cluster
listen: 0.0.0.0:4248
routes: [
nats://192.168.128.52:4248
nats://192.168.128.53:4248
]
}
Bien sûr, il faudra adapter le nom du noeud (et les adresses IP) dans les autres fichiers de configuration.
On peut démarrer NATS à partir de cette configuration via nats-server -c nats.conf -js.
Maintenant que le terrain est prêt, nous pouvons ajouter la partie de l’authentification entre les membres du cluster.
Faisons notre authentification via un couple login/password car malheureusement l’usage des nkeys n’est pas possible pour les serveurs (c’est une feature réservés aux clients des SDKs). Afin d’assurer un minimum de sécurité, nous allons également hasher ces mots de passe.
On peut générer une suite de 22 caractères (le minimum autorisé par NATS) et le hasher via la commande nats server password :
nats server password -p 0XNatrc1FBjk50KqRD1bUvhs
$2a$11$Apn5GAgEMmy81pOMmH3tpetvExWGoh6sm1NsTXqnxnugtGeTDNMnS
Voici donc notre nouveau fichier de configuration (en ajoutant la section cluster.authorization) :
server_name=nats-01
listen=4222
cluster {
name: nats-cluster
listen: 0.0.0.0:4248
authorization {
user: nats
pass: "$2a$11$Apn5GAgEMmy81pOMmH3tpetvExWGoh6sm1NsTXqnxnugtGeTDNMnS"
timeout: 2
}
routes: [
nats://nats:0XNatrc1FBjk50KqRD1bUvhs@192.168.128.52:4248
nats://nats:0XNatrc1FBjk50KqRD1bUvhs@192.168.128.53:4248
]
}
Évidemment, dans un contexte de production, il faudra que chaque serveur ait son propre mot de passe. Faisons simple dans le cadre de notre projet.
Si jamais je tente de me rajouter dans le cluster (sans avoir le mot de passe), je me fais rejeter par les membres de celui-ci.
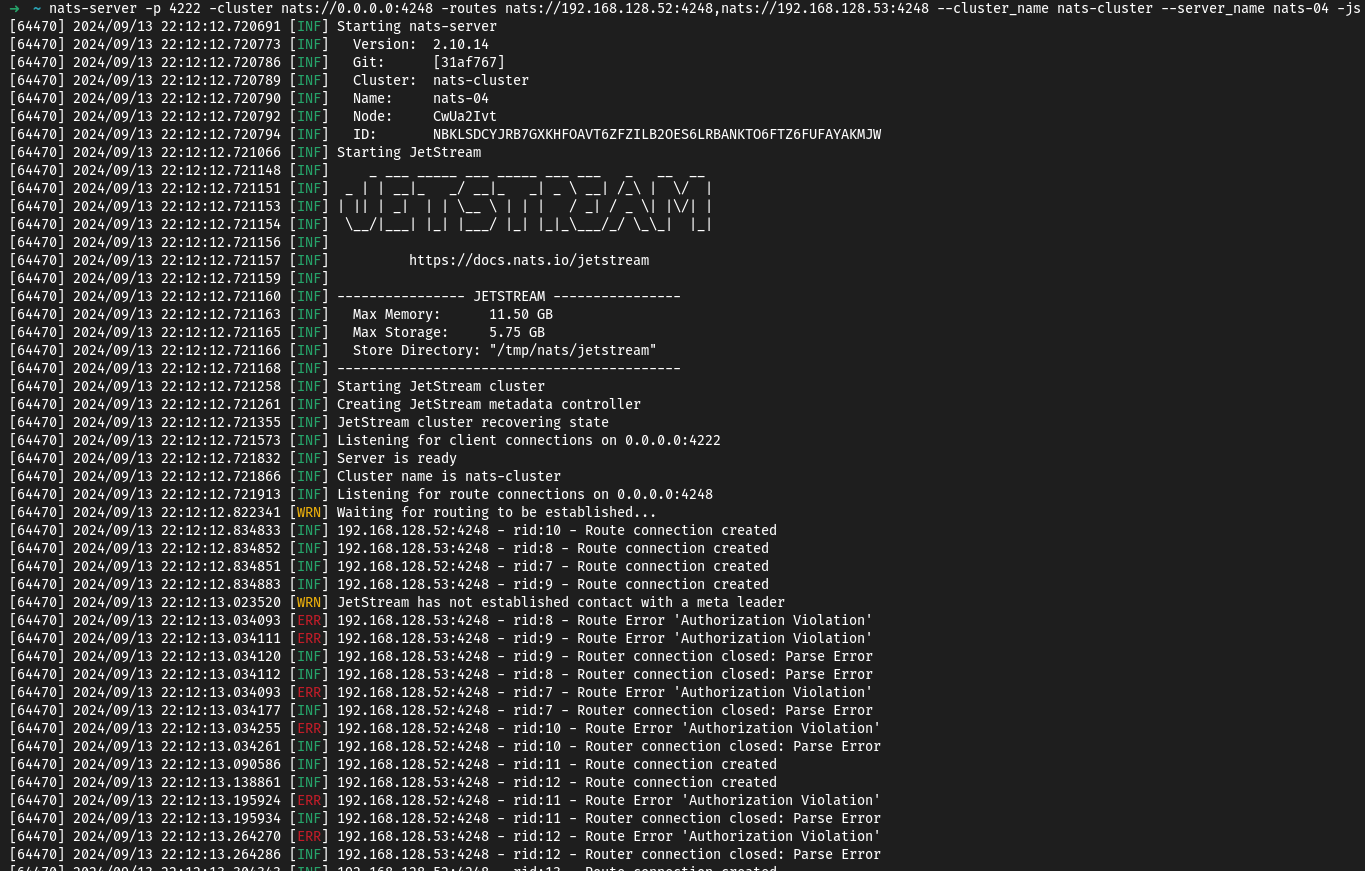
Maintenant, passons aux clients NATS.
Authentifier les clients
Maintenant que notre serveur est “sécurisé” (on a pas non-plus de chiffrement TLS…), nous pouvons restreindre les accès à nos clients.
Je vais d’abord générer un couple d’identifiant “admin” (le client bash ne supporte que le login mTLS ou par identifiants) que nous utiliserons sur la cli :
nats server password -p cdp7uh2zPMu616WMR09B5TcO
$2a$11$td0/m6AnXKCpUDYDdDA24OunSzurHol96802b3QqRzpvVntoNhTd2
Voici le contenu à ajouter dans le fichier de configuration :
authorization {
ADMIN = {
publish = ">"
subscribe = ">"
}
users = [
{user: admin, password: "$2a$11$td0/m6AnXKCpUDYDdDA24OunSzurHol96802b3QqRzpvVntoNhTd2", permissions: $ADMIN}
]
}
Note : cette section est bien présente à la racine du fichier de configuration, à ne pas confondre avec celle utilisée pour l’authentification entre les serveurs.
Faisons un premier test pour valider que nous ne pouvons rien publier sans s’authentifier.
$ nats pub Hello World
nats: error: nats: Authorization Violation
$ nats sub cafe
nats: error: nats: Authorization Violation
Parfait ! Pour nous authentifier, nous allons utiliser la commande nats context edit et ajouter nos identifiants dans notre contexte.
nats context edit coffee-shop
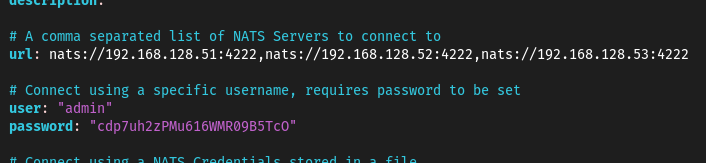
Maintenant que c’est fait, essayons de nouveau de publier sur NATS :
$ nats pub Hello World
22:27:53 Published 5 bytes to "Hello"
$ nats sub hello
22:29:28 Subscribing on hello
Nous sommes bien authentifiés via un login administrateur.
Maintenant, c’est à nos programmes Golang de s’authentifier sur le cluster car dans l’état : plus rien ne fonctionne.
➜ coffee-maker git:(main) ✗ go run main.go
2024/09/13 22:33:06 nats: Authorization Violation
exit status 1
Nous utilisons les clés ed25519 (nkeys) comme source d’authentification. Pour cela, l’outil nk est nécessaire, voici comment l’installer :
go install github.com/nats-io/nkeys/nk@latest
Nous pouvons désormais générer notre certificat comme ci-dessous, celui-ci nous permettra de nous authentifier sur les serveurs NATS.
nk -gen user -pubout
SUAODXP6FI7NG2UUG4TEQPPUXVAYYVPTVE6XBIGOVDYCJCV6C7FNE3MRCA
UBCK5FNECIZDGNQLHSXYBO4RUFAYQ2W2NCFFD3QKKXVCE6QRABAO4W4X
La clé commençant par S (pour Sign) est la clé privée et la clé commençant par U (pour User) est la clé publique.
Ajoutons cette dernière comme étant une machine à café, celle-ci doit pouvoir s’abonner aux topics coffee.orders.* et envoyer sur le coffee.stock.*.dec.*.
authorization {
ADMIN = {
publish = ">"
subscribe = ">"
}
COFFEEMAKER = {
publish = "coffee.orders.*`"
subscribe = "coffee.stock.*.dec.*"
}
users = [
{user: admin, password: "$2a$11$td0/m6AnXKCpUDYDdDA24OunSzurHol96802b3QqRzpvVntoNhTd2", permissions: $ADMIN}
{nkey: UBCK5FNECIZDGNQLHSXYBO4RUFAYQ2W2NCFFD3QKKXVCE6QRABAO4W4X, permissions: $COFFEEMAKER}
]
}
Notre code doit maintenant prendre en compte la clé privée ed25519, pour cela il nous faut la stocker dans un fichier texte seed.txt.
J’aurais bien voulu utiliser des variables d’environnement, mais j’ai l’impression que les développeurs de NATS n’ont pas prévu cette fonctionnalité.
// ...
opt, err := nats.NkeyOptionFromSeed("seed.txt")
if err != nil {
log.Fatal(err)
}
nc, err := nats.Connect(os.Getenv("NATS_URL"), opt)
if err != nil {
log.Fatal("connect to nats: ", err)
}
// ...
Après avoir modifié notre code, nous pouvons lancer notre programme.
$ go run main.go
nats: Permissions Violation for Subscription to "_INBOX.VSS7E6KepvB2bC2d6HTlKr.*" on connection [38]
nats: Permissions Violation for Publish to "$JS.API.STREAM.UPDATE.coffee-orders" on connection [38]
Il semblerait que nous ayons un problème de permission. En effet, il manque les permissions pour gérer les streams et l’INBOX (nécessaire pour les requêtes). Modifions donc celles du groupe COFFEEMAKER:
COFFEEMAKER = {
publish = ["coffee.orders.*`", "$JS.API.STREAM.*.coffee-orders", "$JS.API.CONSUMER.CREATE.coffee-orders.>", "$JS.API.INFO", "$JS.API.STREAM.CREATE.KV_orders-values", "$JS.API.CONSUMER.MSG.NEXT.coffee-orders.coffeeMakers", "$JS.API.CONSUMER.INFO.coffee-orders.coffeeMakers", "$JS.ACK.coffee-orders.coffeeMakers.>", "$KV.orders-values.orders.pending"]
subscribe = ["coffee.stock.*.dec.*", "_INBOX.>"]
}
Information
Prenons quand même le temps d’expliquer la logique derrière ces nouveaux droits :
Remarquez que j’ajoute plusieurs permissions pour les streams. En effet, notre client s’assure toujours que le stream existe en réalisant une “update” sur celui-ci (via le topic $JS.API.STREAM.UPDATE.<stream_name>). Si jamais le stream n’existe pas, il va le créer en publiant sur le topic $JS.API.CONSUMER.CREATE.<stream_name>.<consumer_name>.<topics> (e.g. dans mon cas, il publie sur $JS.API.CONSUMER.CREATE.coffee-orders.coffeeMakers.coffee.orders.*).
Une fois le jetstream (et le consumer) créé, il va s’assurer que le consumer est bien connecté et va demander le prochain message à traiter via le topic $JS.API.CONSUMER.MSG.NEXT.<stream_name>.<topics>.<consumer_name>. Comme nous devons ACK le message, nous devons également avoir la permission $JS.ACK.<stream_name>.<consumer_name>.> (la suite correspondant à l’ID du message, j’utilise le wildcard >).
Puisque nous demandons aussi les informations sur le consumers (pour obtenir le nombre de messages en attente), nous devons également ajouter les permissions pour les topics $JS.API.CONSUMER.INFO.<stream_name>.<consumer_name>. On utilise cette information pour l’envoyer dans le KV store (en le créant via le topic $JS.API.STREAM.CREATE.KV_<bucket> ). Pour stocker dans le KV, la permission $KV.<bucket>.<key> est obligatoire.
Le topic $JS.API.INFO est également nécessaire pour obtenir des informations sur les streams.
On va maintenant ajouter les autres composants et configurer les différentes permissions dans les topics auxquels ils doivent accéder.
authorization {
ADMIN = {
publish = ">"
subscribe = ">"
}
COFFEEMAKER = {
publish = ["coffee.orders.*`", "$JS.API.STREAM.*.coffee-orders", "$JS.API.CONSUMER.CREATE.coffee-orders.>", "$JS.API.INFO", "$JS.API.STREAM.CREATE.KV_orders-values", "$JS.API.CONSUMER.MSG.NEXT.coffee-orders.coffeeMakers", "$JS.API.CONSUMER.INFO.coffee-orders.coffeeMakers", "$JS.ACK.coffee-orders.coffeeMakers.>", "$KV.orders-values.orders.pending", "coffee.stock.>"]
subscribe = ["coffee.stock.*.dec.*", "_INBOX.>"]
}
STOCKMANAGER = {
subscribe = ["coffee.stock.>"]
}
WEBSITE = {
subscribe = [ "_INBOX.>", "$KV.orders-values.orders.pending"]
}
CONTROLLER = {
subscribe = ["_INBOX.>", "coffee.web.requests"]
publish = ["coffee.orders.>", "coffee.stock.>"]
allow_responses = true
}
users = [
{user: admin, password: "$2a$11$td0/m6AnXKCpUDYDdDA24OunSzurHol96802b3QqRzpvVntoNhTd2", permissions: $ADMIN}
{nkey: UBCK5FNECIZDGNQLHSXYBO4RUFAYQ2W2NCFFD3QKKXVCE6QRABAO4W4X, permissions: $COFFEEMAKER}
{nkey: UDBYMBVQOK5RE3WWCIRHQ6BDOKXRN37KMEE3CZUMTWORJX3VEE6QGCTO, permissions: $STOCKMANAGER}
{nkey: UDWQECJ5HQ526PAEPQ54UDHQDQA6JEWDNYSWDXUGD5G6TU2AHGWFZY4W, permissions: $WEBSITE}
{nkey: UCRUD7HB2UHMOGQDLBOOTACTXCZNVLGCJSBRZBWWUTYSE4SIKTN3VTVN, permissions: $CONTROLLER}
]
}
Un dernier soucis persiste (mais il ne semble pas possible de pallier à ce problème pour le moment), les permissions pour faire des requêtes (et en recevoir) nécessitent de pouvoir publier/souscrire aux topics _INBOX.>. Cela signifie que n’importe quel client peut envoyer des requêtes à n’importe quel autre (et recevoir des réponses). Ils peuvent également écouter les réponses des échanges qui ne leur sont pas destinés 😓 .
Pour le moment, nous allons devoir nous contenter de cette solution. J’espère trouver une idée un jour pour régler ce problème.
Conclusion
Notre petit projet commence à prendre forme (vous pouvez consulter le code source ici). Je pense que nous avons vu l’essentiel de ce que je voulais vous montrer à propos de NATS (les streams, le kv store, les requêtes, l’authentification…). Il reste encore d’autres choses à découvrir comme l’object-storage (je l’ai essayé en local, mais je n’ai pas trouvé d’application concrète pour l’utiliser dans ce projet), le déploiement à chaud d’un code lorsqu’un message est envoyé dans un topic précis (avec une intégration à Firecracker), ou encore le fait d’intégrer le serveur NATS dans une application Go.
C’était un format un peu différent de ce que je fais d’habitude (j’ai essayé de faire un peu plus concret en présentant un projet fictif), n’hésitez pas à faire un feedback sur ce format.
J’espère avoir attisé votre curiosité vis-à-vis de NATS. Si cet article en vaut la peine d’après vous (et que vous pouvez vous le permettre), vous pouvez également me faire un don via Ko-fi pour financer les prochaines pages de ce blog.
Je vous dis à bientôt pour un prochain article !